RAG-архитектура для корпоративных данных: как подключить LLM к внутренним документам
Из чего собирается RAG, где он ломается на пилотах и почему чувствительные документы остаются в закрытом контуре

Сотрудник спрашивает у LLM, как согласовать договор на поставку оборудования сверх лимита в 5 миллионов рублей. Модель отвечает уверенно: маршрут согласования, состав визирующих, сроки. Всё звучит правдоподобно. Только регламент в компании пересматривали полгода назад, лимит давно подняли, а часть визирующих переехала в другой блок.
Это типовой сценарий, который объясняет, зачем нужен RAG. Языковая модель умеет хорошо рассуждать, но она не видит ваши договоры, регламенты, проектную документацию, переписку и внутренние базы знаний. Всё это лежит во внутренних системах, к которым у модели нет доступа. И никакой объём публичных данных при предобучении не научит её отвечать про вашу компанию.
Статья будет полезна ИТ-директорам, архитекторам, руководителям ИБ и владельцам корпоративных баз знаний, которые рассматривают подключение LLM к внутренним документам. После прочтения у вас будет понимание, из чего собирается RAG-архитектура, где она ломается на пилотах, какие компоненты разумно рассматривать в 2026 году и почему закрытый контур остаётся базовым требованием для чувствительных данных. RAG — инженерная архитектура с десятками точек настройки, и от качества этой инженерной работы в итоге зависит результат гораздо больше, чем от выбора самой модели.
Почему LLM не знает документы вашей компании
Базовая модель училась на публичных данных: книги, веб, статьи, форумы, открытый код, документация открытых проектов. Ваши договоры, инструкции, протоколы и проектные папки в это пространство не попадали. И не должны были попадать.
Когда сотрудник задаёт модели вопрос про внутренний регламент, у неё нет хорошего варианта. Признаваться в незнании модели обучены не всегда; ответить общими словами в стиле учебника по корпоративному управлению можно, но толку от такого ответа мало. Самый частый и одновременно самый опасный исход — уверенный, правдоподобно звучащий ответ, опирающийся на обобщения из обучающего корпуса. Это и есть галлюцинация: модель не врёт намеренно, она восстанавливает «как обычно бывает» и подставляет это под ваш вопрос. Для пользователя такой ответ выглядит как нормальная справка от системы — в этом основная беда.
Решение «давайте просто положим все документы в промпт» работает плохо по нескольким причинам. Контекстное окно конечно — даже сотни тысяч токенов когда-нибудь заканчиваются, а корпоративный архив легко тянет на десятки гигабайт текста. Стоимость растёт линейно с количеством токенов в запросе. Качество ответа на длинных контекстах деградирует: модель хуже находит факты в середине большого документа. Но даже если бы всё это удалось обойти, остаётся главное: нет никакого механизма, чтобы вытащить актуальную версию регламента и одновременно отсечь данные, к которым у конкретного пользователя нет доступа.
Реальные внедрения упираются именно в это. Документы лежат в SharePoint, файловых шарах, почте, тикет-системах и DMS, у каждого источника свои права, свои версии и свои дубликаты. Всё это нужно как-то подружить с моделью, не отдав ей лишнего и не оставив без нужного.
Что такое RAG простыми словами
Retrieval Augmented Generation — это архитектурный приём, который превращает LLM из «читателя интернета» в «эксперта с архивом под рукой». Перед тем как отвечать, система не просто отдаёт вопрос модели, а сначала идёт в корпоративное хранилище, находит там релевантные фрагменты документов и передаёт их вместе с вопросом.
Запрос пользователя → векторное представление запроса → поиск в индексе → отбор релевантных фрагментов → сборка контекста → запрос к LLM с контекстом → ответ со ссылками на источники.
Аналогия: представьте эксперта, который умеет отлично рассуждать, но плохо помнит подробности конкретных документов. Перед тем как задать ему вопрос, помощник кладёт на стол выдержки из нужных папок. Эксперт читает выдержки и формулирует ответ, опираясь на документы, а не на общую эрудицию.
Разница между обычным ответом LLM и ответом RAG-системы видна сразу. На вопрос «кто согласует договор поставки оборудования свыше 5 миллионов рублей» обычная модель выдаст что-то вроде:
«Обычно такие договоры согласуются юридическим отделом, финансовой службой и руководителем подразделения».
Звучит правдоподобно, но к вашей компании это отношения не имеет. С RAG-системой ответ должен выглядеть иначе:
«Согласно регламенту договорной работы (ред. от 12.03.2026), договоры поставки оборудования на сумму свыше 5 млн рублей согласуются юридическим отделом, финансовым контролёром и директором блока закупок. Для оборудования, подключаемого к объектам КИИ, дополнительно требуется согласование службы ИБ.
Источники: Регламент договорной работы, раздел 4.2; Матрица полномочий, приложение 1».
Это и есть ценность подхода: ответ не только корректнее — он ещё и проверяемый. Пользователь видит, на какой пункт какого документа сослалась система; администратор может посмотреть в журнале, какие источники использовались. На вопрос «откуда модель это взяла» появляется конкретный ответ.
Из этой схемы важно запомнить главное: качество RAG-ответа упирается прежде всего в качество найденного контекста. Самая дорогая модель не вытащит хорошего ответа из плохой выдачи retrieval. Полезно также держать в голове, что RAG не дообучает модель и не «вшивает» документы внутрь её весов — документы и индекс продолжают жить в корпоративном хранилище, никуда не «утекая» в саму LLM.
Базовая RAG-архитектура
В типовой корпоративной реализации RAG-система собирается из нескольких связанных частей. Каждая отвечает за свой кусок цепочки и имеет собственные настройки качества.
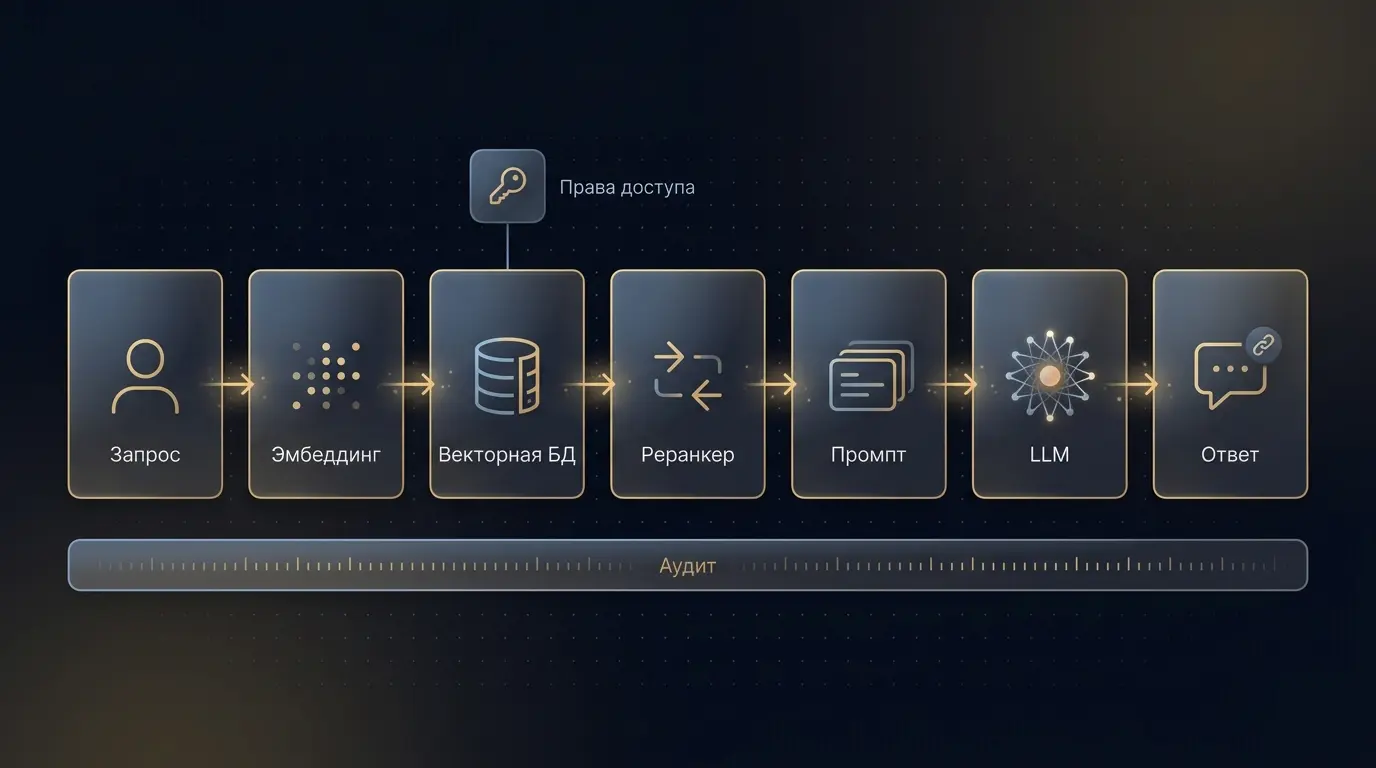
RAG-конвейер: путь от вопроса пользователя до ответа со ссылками на документы
PDF, DOCX, Confluence, DMS, договоры, инструкции, тикеты, переписка. Конвейер загружает документы и запускает обработку при изменениях.
Парсеры PDF и Office, OCR для сканов, обработка таблиц, удаление шапок, подвалов и сквозной нумерации страниц.
Разбиение документов на фрагменты с учётом структуры и перевод фрагментов в векторы локальной embedding-моделью.
Хранилище векторов с поиском по сходству и фильтрацией по метаданным — включая права доступа.
Cross-encoder переставляет кандидатов по точному соответствию запросу, prompt builder собирает финальный промпт из вопроса и фрагментов.
Генерация ответа, ссылки на конкретные документы, логирование запросов и ответов в корпоративный SIEM.
На красивой схеме всё выглядит просто. На реальном проекте основное время съедает совсем не модель: нужно разобрать форматы, договориться с владельцами систем, навести порядок в правах, настроить chunking так, чтобы куски документов имели смысл, и научить retriever находить нужное при нечётких формулировках. Эти задачи редко всплывают в презентациях, но именно они решают, заработает система или нет.
Компоненты RAG: что выбирать в России в 2026 году
Никакой «единственно правильной» сборки нет. Выбор зависит от требований к контуру, размера корпуса, языкового профиля документов и готовности команды поддерживать инфраструктуру.
Embedding-модели
Для русского языка и корпоративной документации в проектах часто рассматривают модели семейства multilingual-e5 и bge-m3 — они доступны как open-source и работают локально. На рынке также присутствуют Yandex Embeddings и sbert-large-nlu-ru, выбор зависит от того, разрешено ли отправлять данные во внешний API и как устроена политика поставщика. Для специализированных доменов (юридический, медицинский, инженерный) общие модели могут давать слабую релевантность — иногда стоит дообучать собственный энкодер на парах «вопрос — фрагмент».
Vector store
FAISS — это библиотека Meta для поиска по векторам, удобная для прототипов и встроенных решений, но не сервер БД в полном смысле. Qdrant — векторная БД на Rust с поддержкой фильтрации по метаданным, что критично для разграничения прав доступа на этапе поиска. OpenSearch удобен, когда нужен гибридный поиск: классический BM25 плюс векторный, в одном движке. Milvus масштабируется на большие корпуса, но требует более серьёзной эксплуатации. Для пилота на одном узле часто выбирают Qdrant; для интеграции с уже существующим стеком ELK или OpenSearch — последний.
Reranker
Это второй этап поиска: первичный retriever отдаёт, скажем, 30 кандидатов, а cross-encoder reranker оценивает каждую пару «запрос — фрагмент» и переставляет результаты. На маленьких корпусах с непохожими документами без него можно обойтись. На большом архиве, где есть множество регламентов с похожей структурой, reranker заметно повышает точность ответа: верхние 3–5 фрагментов становятся существенно релевантнее.
LLM
Здесь разделение проходит по контуру данных. Для чувствительных корпусов и работы по требованиям ИБ обычно выбирают open-source модель, развёрнутую в закрытом контуре. Если данные разрешено отправлять во внешний сервис, проще взять коммерческую модель по API — это быстрее в развёртывании и снимает с команды нагрузку по поддержке инфраструктуры. Гибридные схемы, где чувствительная часть обслуживается локальной моделью, а публичная — внешней, встречаются реже, но иногда оказываются разумным компромиссом. Подробнее об этом — в материале про on-premise LLM.
| Компонент | Возможные варианты |
|---|---|
| Embedding-модель | bge-m3, multilingual-e5, Yandex Embeddings, sbert-large-nlu-ru, кастомные |
| Vector store | Qdrant, OpenSearch, Milvus, FAISS |
| Reranker | bge-reranker-v2-m3, cross-encoder на ru |
| LLM | Open-source в контуре, коммерческие API, гибрид |
Перечисленные варианты — ориентировочные. Окончательный выбор делается под конкретный сценарий, корпус и требования ИБ.
Подводные камни RAG-проектов
Большая часть проблем RAG возникает ещё до этапа генерации — в подготовке корпуса и retrieval. LLM здесь, как правило, не виновата.
Плохой chunking. Слишком короткие фрагменты теряют контекст: пункт регламента без заголовка раздела превращается в обрывок. Слишком длинные размывают релевантность: в одном чанке смешаны несколько тем, и поиск находит фрагмент по одной теме, а отвечать пытается на другую. Разумный диапазон обычно 300–800 токенов с перекрытием, но для договоров и регламентов лучше резать по структуре документа: разделы, статьи, пункты.
Дубликаты и старые версии. В типичной корпоративной файловой шаре одного и того же документа лежит несколько копий разной свежести. Если не отсеять их на ingestion, retriever будет находить версию двухлетней давности с равной вероятностью. Помогают хеши содержимого, дедупликация по нормализованному тексту и явная маркировка актуальной версии в метаданных.
Без подразделения, типа документа, даты, владельца и грифа конфиденциальности невозможно ни отфильтровать выдачу по правам доступа, ни понять, какой документ показывать пользователю. По важности метаданные сопоставимы с самими документами; на пилоте ими часто пренебрегают, на проде потом переделывают всё заново. Сюда же относится разрыв между языком пользователей и языком документов: архитектор закладывает поиск по «согласованию договора», а пользователи пишут «как подписать контракт». На таких разрывах теряется значительная часть релевантности; помогают синонимические словари, гибридный поиск и расширение запроса.
Перегруженный контекст. Соблазн положить в промпт «побольше фрагментов на всякий случай» — типовая ошибка. Модель начинает теряться, отвлекается на нерелевантное и иногда смешивает сведения из разных документов. Лучше отдать 3–5 точных фрагментов, чем десяток размытых.
Отсутствие ссылок на источники и оценки качества. Без ссылок пользователь не может проверить ответ, без метрик — никто не знает, лучше ли стало после изменений. Минимум: тестовый набор из 50–100 реальных вопросов с эталонными документами, регулярный замер top-k accuracy и качества ответа.
Отдельно стоит проговорить вещь, которая регулярно теряется в инженерной части: права доступа должны фильтровать выдачу retrieval до того, как фрагменты дойдут до LLM. Если ограничения накладываются только на интерфейсе, в момент генерации модель видит документы, которых пользователь видеть не должен — даже если в финальный ответ они не попадут. Это уже не инженерная, а ИБ-проблема: RAG-система не должна становиться обходным путём вокруг существующей корпоративной модели доступа.
И ещё одно требование, которое всплывает обычно после запуска: корпоративная RAG-система должна уметь не отвечать. Если в найденных фрагментах нет основания для ответа, лучшая реакция — сказать об этом прямо, а не собирать «правдоподобную» версию из общих рассуждений. Для пользователя честное «в документах ответа нет, обратитесь к владельцу регламента» полезнее уверенно сформулированной выдумки.
| Проблема | Что делать |
|---|---|
| Слишком крупные чанки | Резать по разделам, держать 300–800 токенов |
| Дубликаты документов | Дедупликация на ingestion, маркировка актуальной версии |
| Нет метаданных | Обязательные поля: владелец, тип, дата, гриф |
| Разрыв языка запросов и документов | Гибридный поиск, синонимы, расширение запроса |
| Нет reranker | Cross-encoder reranker поверх первичной выдачи |
| Перегруженный контекст | Жёстко ограничить число фрагментов |
| Нет ссылок и метрик | Цитирование источников, тестовый набор и регулярные замеры |
Попытка одной LLM решить организационный беспорядок в документах обречена. Если на файловом сервере лежит несколько разнящихся версий регламента и ни в одной нет даты последней редакции, никакая RAG-архитектура не сделает поиск надёжным.
Когда RAG не нужен
RAG — не универсальный ответ. Несколько случаев, когда стоит выбрать другой инструмент.
Prompt engineering. Если задача укладывается в один промпт с парой примеров — например, классификация обращений или извлечение полей из счёта, — никакого retrieval не нужно. Сложная архитектура только замедлит и удорожит решение.
Fine-tuning. Дообучение полезно, когда нужно изменить поведение модели: формат ответа, тон, узкоспециализированный жаргон, классификационные паттерны. Заставлять модель «запомнить» свежие документы через fine-tuning неэффективно: каждое обновление корпуса требует нового цикла дообучения, а ссылки на источники из ответа исчезают.
Часть сценариев решается без LLM вообще. Если пользователям достаточно увидеть документ, а не получить готовую формулировку, классический поисковый движок (Elasticsearch, OpenSearch с BM25) дешевле и понятнее. Внутренний портал с разделами, тегами и нормальной поисковой строкой нередко закрывает задачу лучше любого генеративного ответа — особенно если документы стабильны и активно посещаются.
Workflow-автоматизация без LLM. Рутинные операции с предсказуемыми правилами — согласования, маршрутизация, проверки полей — почти всегда лучше делать классически: BPM, RPA, скрипты.
Иногда честный ответ заказчику звучит так: вам сейчас нужен не RAG, а порядок в DMS и ревизия прав доступа. После этого RAG станет осмысленным.
On-premise RAG для корпоративных данных
Для российских корпоративных и государственных заказчиков, объектов КИИ, банков, промышленности и любых организаций, которые работают с персональными данными или коммерческой тайной, вопрос «куда уходят документы» закрывает значительную часть дискуссии о выборе архитектуры. Закрытый контур на собственной инфраструктуре даёт несколько практических вещей.
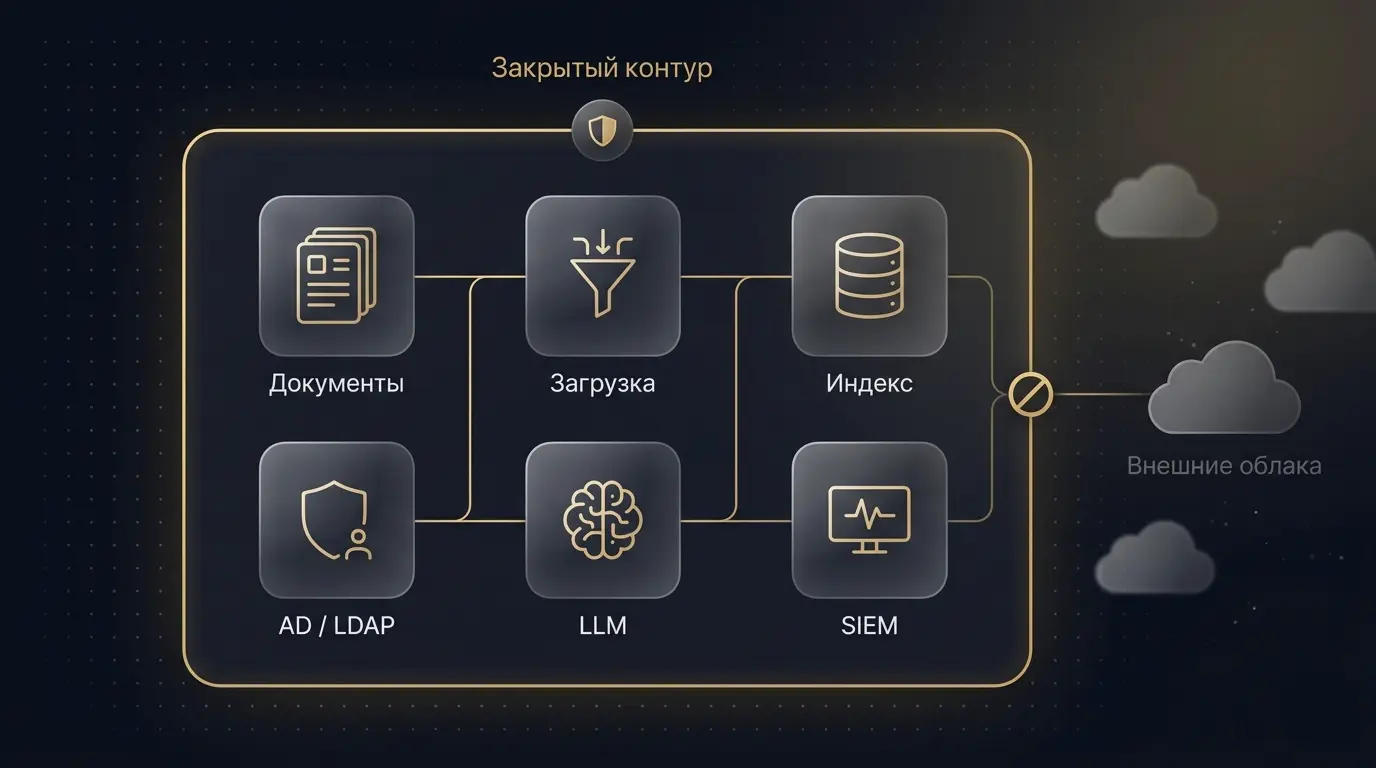
Закрытый контур: документы, индекс и LLM не покидают корпоративный периметр
Документы и индексы остаются под контролем компании. Embedding'и, в которые превращаются фрагменты, тоже хранятся локально, что важно: вектор хорошей размерности фактически восстанавливает смысл фрагмента и при компрометации индекса считается чувствительным активом. Этой же логики — что вектор может «протекать» — касается и материал про защиту данных в LLM.
Запросы пользователей и сгенерированные ответы можно логировать в SIEM, фиксировать кто, что и когда спросил. Систему можно интегрировать с AD и LDAP для авторизации, с DLP для проверки исходящих ответов, со внутренней почтой и тикет-системами как источниками контекста. Закрытый контур упрощает разговор со службой безопасности и юристами: на схеме чётко видно, что данные не покидают периметр. Это снижает количество согласований и облегчает прохождение проверок по требованиям ИБ.
При этом on-premise RAG не бесплатен и не всегда лучше во всех смыслах. Он требует GPU-инфраструктуры под локальную модель и embedding'и, отдельной поддержки, мониторинга, планирования обновлений, периодической переиндексации. Команда должна уметь эксплуатировать стек, а не только запускать прототипы. Если все документы публичны, а сценарий простой, облачное решение может быть быстрее и дешевле. Для чувствительных данных закрытый контур обычно оказывается единственным приемлемым вариантом — но именно «приемлемым», а не «дешёвым».
Кейс AzoneDoc: как RAG применяется в закрытом контуре
AzoneDoc — система AZONE-AI для работы с внутренними документами на базе RAG-подхода, разворачиваемая в закрытом контуре заказчика.
Постановка задачи у заказчика обычно звучит примерно так: документы у нас есть, но сотрудники не всегда знают, где лежит актуальная версия, кому её можно показывать и какой пункт применять в конкретной ситуации. RAG в закрытом контуре отвечает именно на это.
Если описывать концептуально, без деталей конкретных внедрений, в типовой реализации цепочка выглядит так. Документы загружаются в защищённый контур через коннекторы к корпоративным источникам или прямой выгрузкой. Система извлекает текст, очищает его от служебных элементов, разбивает на фрагменты с учётом структуры документа и считает векторные представления с помощью локальной embedding-модели. Индекс и метаданные хранятся в векторной БД внутри контура. Пользователь задаёт вопрос через интерфейс, система применяет фильтры по правам доступа на этапе поиска, отбирает релевантные фрагменты, проводит их через reranker, собирает контекст и передаёт его локальной LLM. В ответе пользователь видит не только сформулированный текст, но и ссылки на конкретные документы и фрагменты, на которые опирался ответ. Подробнее об опыте развёртывания подобных систем — в кейсе AzoneDoc.
Что это даёт компании на практике. Поиск по регламентам и договорам ускоряется в разы — особенно когда нужно собрать ответ по нескольким связанным документам. Снижается нагрузка на экспертов, которым раньше задавали повторяющиеся вопросы. Уменьшается риск ответа «из головы»: ссылки на источники видны пользователю, ответ можно проверить. И главное — LLM работает там, где её невозможно использовать иначе: в контурах с персональными данными, коммерческой тайной, требованиями ФСТЭК и внутренними регламентами ИБ, запрещающими отправку документов в публичные облака.
Качество ответов в такой системе зависит от того, как подготовлен корпус, как описаны метаданные и насколько чётко настроены права доступа. Поэтому внедрение AzoneDoc начинается с инвентаризации документов и сценариев — обсуждение конкретной модели обычно идёт уже потом, на основе понятых требований.
Как начать пилот RAG-проекта
Хороший пилот не пытается охватить весь корпоративный архив. Он берёт один понятный сценарий и доводит его до рабочего состояния. Подробный гайд по инфраструктуре — в руководстве по развёртыванию LLM в закрытом контуре.
Поиск по регламентам HR, ответы по договорной библиотеке, помощь техподдержке по базе знаний — что-то одно.
500–5 000 документов достаточно, чтобы проверить архитектуру и не утонуть в подготовке.
Отдельный шаг, который часто пропускают и потом жалеют. Хеши, нормализация, маркировка актуальной версии.
Кто и какие документы может видеть, какие метаданные нужны для фильтрации на этапе retrieval.
Подобрать параметры под структуру документов: договоры режутся иначе, чем инструкции.
Под закрытый контур, с учётом языка документов и готовности команды эксплуатировать стек.
Подобрать число кандидатов, протестировать с reranker и без, замерить разницу на реальных вопросах.
50–100 реальных формулировок от пользователей с эталонными документами для каждого вопроса.
Top-k accuracy для retrieval, экспертная оценка ответов, время ответа, доля цитированных источников.
Ограниченная группа реальных пользователей, обратная связь, итеративные улучшения корпуса и параметров.
Хороший пилот — это не «развернуть LLM и подключить документы». Это способ заранее увидеть, насколько корпус документов готов к промышленной эксплуатации и насколько ответы реально полезны пользователям. Если на ограниченном сценарии retrieval работает плохо, расширять охват бессмысленно — масштабирование только умножит проблемы.
Выводы
RAG — архитектурный подход, в котором качество системы складывается из десятков взаимосвязанных решений: chunking, метаданные, embedding, retriever, reranker, права доступа, ссылки на источники. Ни один отдельный компонент не определяет результат в одиночку. Базовая же LLM без корпоративного контекста не решает задачу работы с внутренними знаниями: она даёт правдоподобные, но не основанные на ваших документах ответы.
Самая дорогая часть RAG-проекта приходится на подготовку корпуса, описание метаданных и интеграцию с источниками. Эту работу нельзя делегировать алгоритмам, и от её качества зависит больше, чем от выбора модели. Для чувствительных корпоративных данных закрытый контур остаётся базовым требованием. Облачные API быстрее и дешевле, но в КИИ, банках и промышленности их применимость ограничена.
Начинать стоит с пилота на одном сценарии и ограниченном корпусе. Попытка проиндексировать весь корпоративный архив с первого дня обычно заканчивается долгим проектом без видимого результата.
Если вы хотите проверить, подойдёт ли RAG для ваших внутренних документов, AZONE-AI может провести экспресс-аудит корпуса данных и предложить архитектуру пилота в закрытом контуре. Мы оценим качество корпуса, состояние метаданных, требования по правам доступа и реалистичные сценарии — оставьте заявку на консультацию.
Частые вопросы
Что такое RAG простыми словами?
RAG (retrieval augmented generation) — это архитектура, при которой LLM перед ответом получает релевантные фрагменты из корпоративных документов. Модель не «учит» документы, а опирается на них при генерации ответа. Это позволяет работать с актуальными внутренними знаниями без переобучения.
Чем RAG отличается от fine-tuning?
Fine-tuning меняет веса модели и подходит для изменения поведения: формата ответа, стиля, классификации. RAG не трогает модель, а подаёт ей нужные документы во время запроса. Для актуальных корпоративных знаний RAG практичнее: документы обновляются без перетренировки модели и видны как ссылки в ответе.
Можно ли использовать RAG в закрытом контуре?
Да, и для чувствительных данных это базовый сценарий. В закрытом контуре разворачиваются embedding-модель, векторная БД и LLM — данные не покидают периметр. Это типовая архитектура для КИИ, банков, промышленных и государственных заказчиков.
Какая векторная база лучше для RAG?
Однозначно «лучшей» нет. Qdrant удобен для пилотов и средних корпусов, OpenSearch — когда нужен гибридный поиск (BM25 плюс векторный), Milvus масштабируется на большие объёмы, FAISS подходит для встроенных решений и прототипов. Выбор зависит от объёма данных, требований к фильтрации по метаданным и существующего стека.
Почему RAG иногда даёт неправильные ответы?
Чаще всего проблема не в LLM, а в retrieval. Плохой chunking, дубликаты, отсутствие метаданных, разрыв между языком запросов и языком документов, отсутствие reranker — каждая из этих причин снижает качество. LLM лишь синтезирует ответ из того, что ей передали; если контекст плохой, ответ будет плохим.
Подходит ли RAG для конфиденциальных документов?
Подходит, если развёрнут в закрытом контуре с разграничением прав доступа на уровне retrieval, аудитом запросов и интеграцией с DLP и SIEM. Документы не отправляются в публичные API, индексы остаются у заказчика. Для коммерческой тайны и персональных данных это рабочая архитектура; внешние облачные сервисы в таких сценариях обычно неприменимы.
Актуальность материала
- Материал подготовлен по состоянию на май 2026 года.
- Перечисленные embedding-модели, vector store и reranker — ориентир для корпоративных проектов. Окончательный выбор делается под конкретный сценарий, корпус и требования ИБ.
- Описание AzoneDoc дано концептуально. Конкретный состав компонентов, объём и сроки внедрения определяются по итогам аудита у заказчика.
Технический документ: Архитектура внедрения LLM в закрытом контуре КИИ
PDF ~20 страниц для CISO и архитекторов. Регуляторный контекст, эталонная архитектура, чек-лист готовности к пилоту.
Запустите RAG на своём корпусе документов
За 4–8 недель мы проведём экспресс-аудит корпуса и соберём пилот RAG в закрытом контуре заказчика. Лицензии ФСТЭК, ФСБ и МО РФ. Опыт с 2003 года.