Как развернуть LLM в закрытом контуре: пошаговое руководство
Llama, Mistral или Qwen? Сравнение моделей, квантизация, vLLM vs TGI, требования к железу — всё для ИБ-специалистов и технических руководителей.
Компания получает доступ к облачному ChatGPT через API. Через два месяца выясняется, что сотрудники отправляли в промпты фрагменты конструкторской документации, персональные данные клиентов и тексты внутренних регламентов. Знакомая ситуация? Именно так обычно начинается разговор о развёртывании LLM on-premise — не с технического интереса, а с конкретного инцидента.
Эта статья — практическое руководство для тех, кто уже решил, что локальная LLM для компании нужна, но пока не понимает, с какого конца подступиться. Разберём выбор модели, инфраструктуру, инструменты инференса и типовые ошибки — без рекламы и без иллюзий.
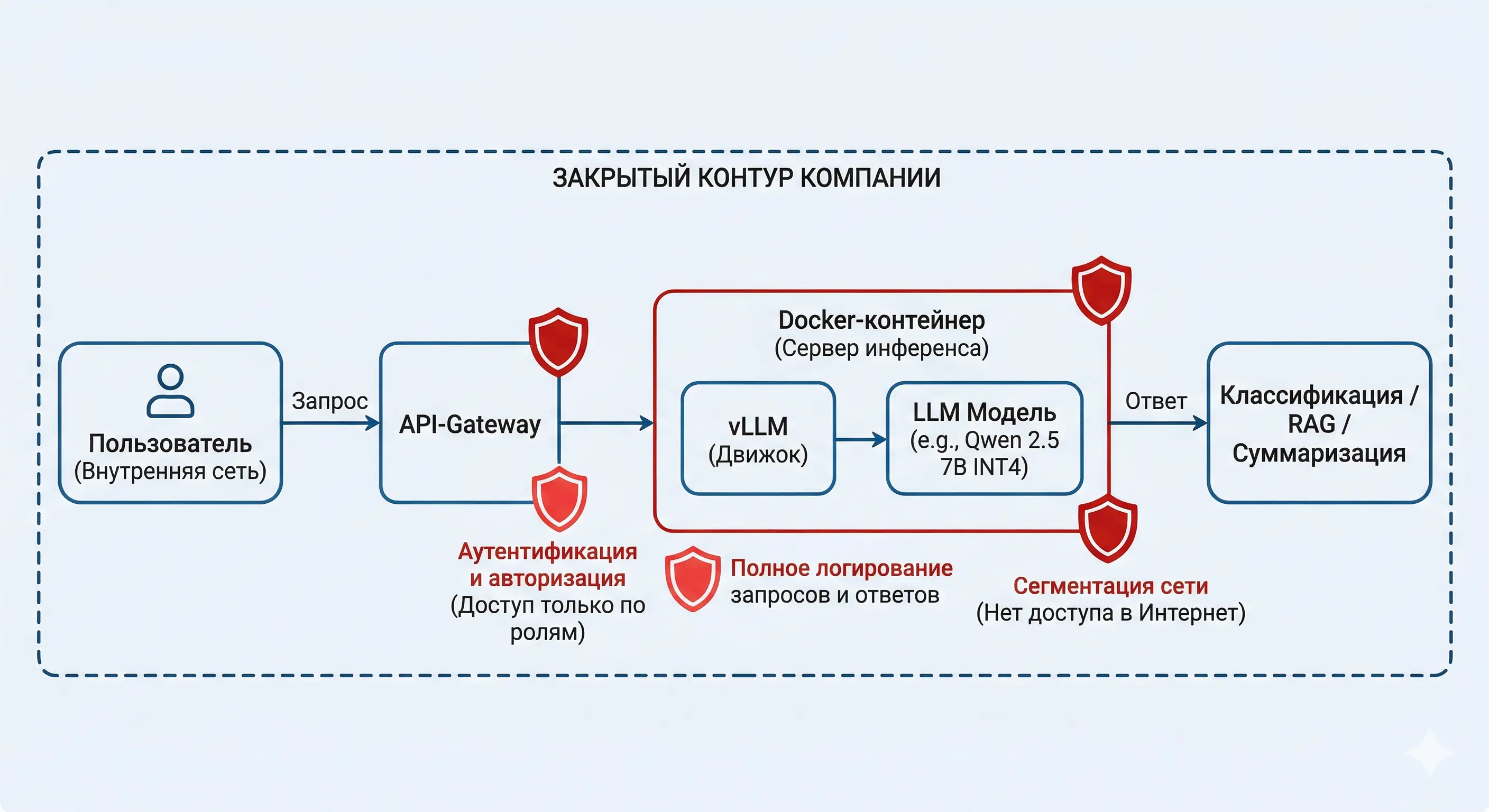
Путь запроса в закрытом контуре: пользователь → API-gateway → vLLM → модель → ответ. Точки контроля ИБ выделены
Почему «просто поднять модель на сервере» — не решение
Интерес к LLM в закрытом контуре вырос не из-за моды. Причины практические: ужесточение требований регуляторов (152-ФЗ, отраслевые стандарты ИБ), рост стоимости облачных API при масштабировании, а также нежелание отдавать конфиденциальные данные третьей стороне — даже если эта сторона обещает их не хранить.
Но между решением «нам нужна своя LLM» и работающим сервисом лежит цепочка нетривиальных инженерных решений. Поставить Docker-контейнер с моделью — это не развёртывание. Это эксперимент. Развёртывание LLM on-premise — это когда модель устойчиво обслуживает пользователей, укладывается в бюджет по железу, не деградирует под нагрузкой и вписывается в ИБ-инфраструктуру: сегментация сети, логирование, контроль доступа.
Когда закрытый контур оправдан: данные не должны покидать периметр (ПДн, гостайна, КТ); регуляторные требования запрещают облако; нужна предсказуемость затрат; нужен полный контроль над поведением модели, включая файнтюнинг.
Когда избыточен: задача — отвечать на типовые вопросы по публичной базе знаний, объём невелик. Облачный API будет дешевле и проще.
Какие задачи решают в закрытом контуре
Ключевой критерий: данные чувствительны, объём запросов предсказуем, а требования к качеству ответов измеримы. Если задача размыта — «пусть ИИ нам что-нибудь полезное подскажет» — пилот почти гарантированно провалится вне зависимости от модели.
Как выбрать модель: Llama, Mistral или Qwen
Выбор модели — решение, на которое тратят больше всего времени. И часто зря, потому что выбирают по бенчмаркам, а не по реальным требованиям задачи. Разберём три наиболее зрелых семейства open-source LLM для on-premise.
Llama 3.x / 4 (Meta AI)
Размеры: 8B – 405B (dense); Scout / Maverick (MoE)
+ Стабильно высокое качество, крупнейшая экосистема адаптеров, максимальная поддержка во всех фреймворках. Огромное сообщество — любая проблема уже решена на GitHub.
− Русский язык из коробки средний — приемлемо для классификации, слабее в генерации связного текста.
→ Универсальный выбор, когда приоритет — стабильность и сообщество
Mistral / Mixtral (Mistral AI)
Размеры: 7B, 8×7B, 8×22B, Small, Large
+ Отличное следование инструкциям — самый «дисциплинированный» из тройки. Mixtral MoE даёт качество 70B-модели при активации лишь 12.9B параметров. Лицензия Apache 2.0.
− Русский лучше Llama, но хуже Qwen. Крупные модели требуют больше VRAM, чем аналоги.
→ Многоязычность, точное следование инструкциям, работа с длинными документами
Qwen 3.x (Alibaba Cloud)
Размеры: 0.6B – 32B (dense); MoE-варианты 30B–235B+
+ Лидер по мультиязычности — десятки языков с хорошей грамматикой, включая русский. Qwen-Coder конкурирует с лучшими в генерации кода. Лицензия Apache 2.0.
− Экосистема и туториалы менее зрелые, чем у Llama.
→ Русский язык, код, структурированные данные, математика
| Критерий | Llama | Mistral | Qwen |
|---|---|---|---|
| Качество ответов | ★★★★★ | ★★★★ | ★★★★★ |
| Код и данные | ★★★★ | ★★★★ | ★★★★★ |
| Русский язык | ★★★ | ★★★★ | ★★★★★ |
| Следование инструкциям | ★★★★ | ★★★★★ | ★★★★ |
| Эффективность | ★★★★ | ★★★★★ | ★★★★ |
| Экосистема | ★★★★★ | ★★★★ | ★★★ |
| Лицензия | Community | Apache 2.0 | Apache 2.0 |
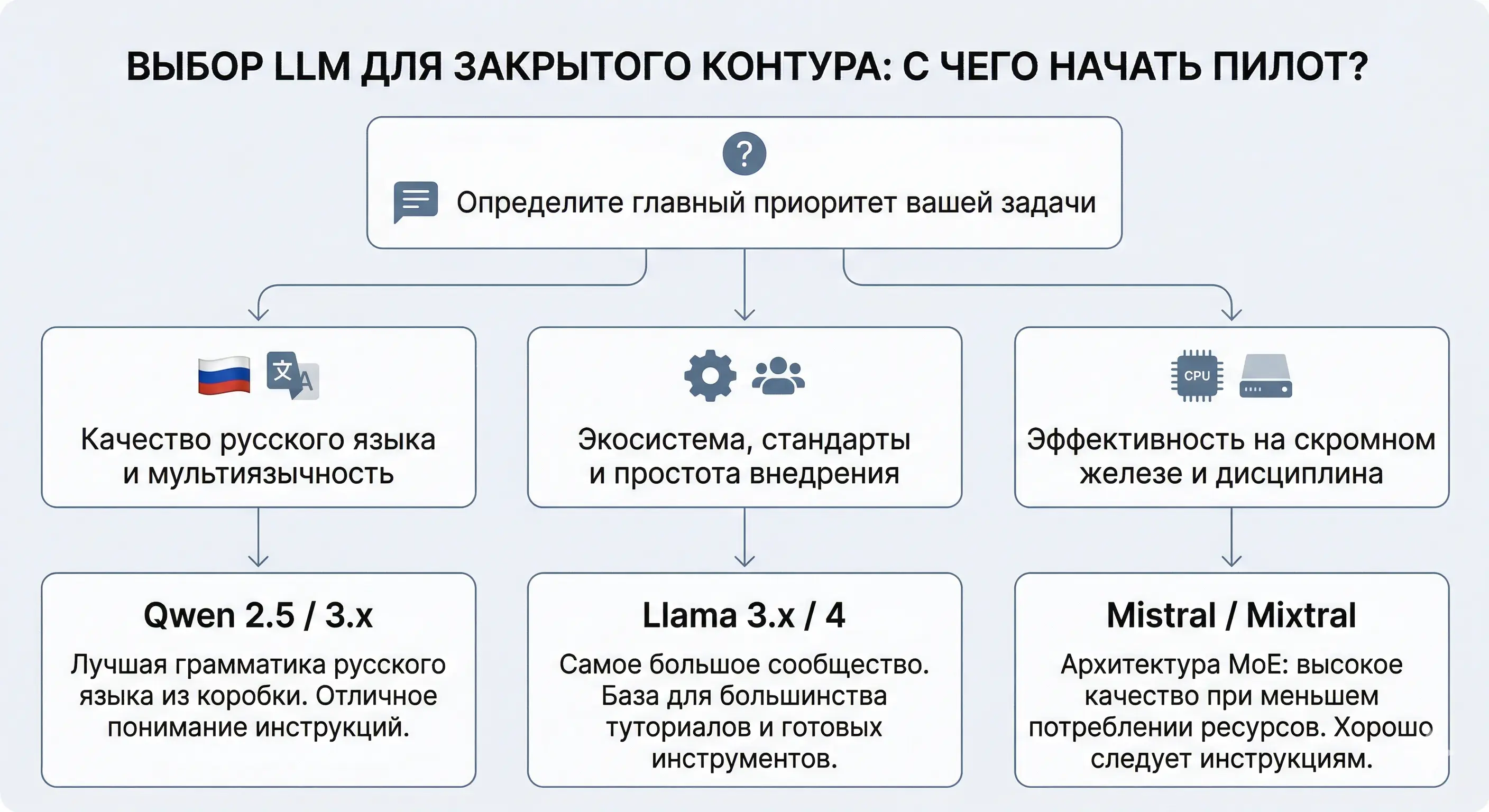
Стартовый вопрос → приоритет задачи → рекомендация модели
Практический совет: не тратьте недели на выбор «идеальной» модели. Возьмите Llama 3.x 8B или Qwen 3.x 8B для пилота — они развернутся за час. Финальный выбор делайте после теста на реальных данных.
Что нужно знать о квантизации
Квантизация LLM — это снижение точности числовых представлений весов модели. Вместо 16-битных чисел (FP16) используются 8-битные (INT8), 4-битные (INT4) или промежуточные форматы. Зачем? Чтобы модель поместилась в меньший объём видеопамяти и работала быстрее.
Цифры говорят сами за себя: модель на 70 миллиардов параметров в FP16 требует около 140 ГБ VRAM. В формате INT4 — примерно 35–40 ГБ. Разница — между кластером из нескольких GPU и одним A100 80 ГБ.
GPTQ
Постобучающая квантизация с калибровочным датасетом. Стабильный, проверенный вариант. Хорошо поддерживается в vLLM и TGI.
AWQ
Activation-aware Weight Quantization — учитывает распределение активаций. Чуть лучшее качество при том же сжатии. Поддержка в vLLM.
GGUF
Формат llama.cpp, оптимизирован для CPU-инференса и гибридных сценариев (CPU + GPU). Основной вариант при отсутствии мощной GPU.
bitsandbytes (NF4/FP4)
Квантизация на лету, не требует подготовки. Удобно для экспериментов, менее производительно в продакшене.
| Модель | FP16 | INT8 | INT4 |
|---|---|---|---|
| 7–8B | ~14–16 ГБ | ~8 ГБ | ~4–5 ГБ |
| 13–14B | ~28 ГБ | ~14 ГБ | ~7 ГБ |
| 70B | ~140 ГБ | ~70 ГБ | ~35–40 ГБ |

7B, 13B, 70B — требования к VRAM при разных уровнях квантизации и подходящие GPU
Практический совет: не квантизуйте «для экономии» модель, которая и так помещается в GPU. Начинайте с FP16, и если не хватает памяти — переходите на INT8, затем INT4. Каждый шаг вниз сопровождайте валидацией на вашем конкретном наборе тестов. INT8 обычно даёт минимальные потери; INT4 заметнее снижает качество на задачах рассуждения.
Что выбрать для инференса: vLLM или TGI
Когда модель выбрана и квантизована, нужен движок, который будет её обслуживать: принимать запросы, управлять очередями, эффективно использовать GPU. Два основных варианта — vLLM и TGI (Text Generation Inference от Hugging Face).
Важный контекст: в декабре 2025 года Hugging Face перевёл TGI в режим maintenance mode. Новые фичи больше не добавляются, принимаются только баг-фиксы. Для новых проектов HF рекомендует vLLM или SGLang. TGI по-прежнему стабилен и проверен — но вектор развития сместился.
| Параметр | vLLM | TGI |
|---|---|---|
| Пропускная способность | Выше при высокой конкурентности (до 24× в пиковых сценариях) | Хорошая; сильная сторона — длинные контексты (до 13× на промптах 200K+ токенов) |
| Задержка (latency) | Стабильная, масштабируется линейно | Ниже tail-latency при 1–2 пользователях |
| API | OpenAI-совместимый из коробки | OpenAI-совместимый + SSE-стриминг |
| Поддержка моделей | Широчайшая, новые архитектуры быстрее | Все основные семейства, новые — сложнее |
| Квантизация | AWQ, GPTQ, FP8 | GPTQ, bitsandbytes, EETQ, FP8 |
| Мониторинг | Базовый, требует доработки | Prometheus + OpenTelemetry из коробки |
| Простота запуска | pip install + одна команда | Docker-контейнер, больше конфигурации |
| Статус проекта | Активно развивается, де-факто стандарт | Maintenance mode с декабря 2025 |
Текущий стандарт индустрии, OpenAI-совместимый API, самая широкая поддержка моделей, самое активное сообщество.
Стабилен, хорошо мониторится, подходит для задач с низкой задержкой. Планируйте миграцию в среднесрочной перспективе.
Практический совет: выбор инференс-движка влияет на пропускную способность, но не на качество ответов — это определяется моделью. Также стоит присмотреться к SGLang — молодой, но быстро растущий проект, который HF рекомендует наряду с vLLM.
Требования к инфраструктуре и железу
Самый частый вопрос: «Какой сервер нужен?» Ответ зависит от размера модели, квантизации, нагрузки и бюджета. Главное ограничение — VRAM: именно объём видеопамяти определяет, какую модель вы сможете запустить.
| Параметр | 7–8B (INT4) | 70B (INT4) | 70B (FP16) |
|---|---|---|---|
| GPU VRAM | 6–8 ГБ (min), 24 ГБ (комфортно) | 35–40 ГБ → 1× A100 80 ГБ | 140+ ГБ → 2× A100 80 ГБ |
| RAM | 32 ГБ | 64–128 ГБ | 128–256 ГБ |
| CPU | 8+ ядер | 16–32 ядра | 32+ ядра |
| Диск | 50 ГБ SSD | 150 ГБ NVMe | 300+ ГБ NVMe |
| Сеть | 1 Gbps | 10 Gbps | 10–25 Gbps (NVLink) |
| Пользователи | 5–15 | 20–50 | 50–100 |
| GPU (ориентир) | RTX 4090 / A10G | 1× A100 80 ГБ | 2× A100 / H100 |
Пошаговый план внедрения
Внедрение LLM в закрытом контуре — проект, а не разовая установка. Весь путь от идеи до пилота занимает 2–4 недели при наличии железа и компетенций.
Определите конкретный кейс
Не «внедрить ИИ», а «сократить время подготовки ответа на тендерный запрос с 4 часов до 30 минут». Измеримая цель — основа адекватного пилота.
Оцените данные
Какие данные будет обрабатывать модель? Есть ли ПДн, КТ, гостайна? Нужно ли согласование с ИБ-службой? Какие требования к логированию?
Выберите модель и формат
Для пилота — 7–8B в INT4. Достаточно, чтобы проверить гипотезу. Не начинайте с 70B: потратите месяцы на железо, а потом кейс может не сработать.
Подготовьте инфраструктуру
Выделите сервер с GPU. Убедитесь, что сетевая сегментация позволяет обращаться к сервису, но не даёт модели доступ в интернет.
Разверните инференс-сервер
vLLM + Docker — минимальная конфигурация с рабочим API за 30–60 минут. Проверьте endpoint, загрузку модели, стриминг.
Интегрируйте с рабочим процессом
RAG-пайплайн, чат-интерфейс, API-интеграция — подключите модель к реальной задаче. Здесь становится понятно, подходит модель или нет.
Проведите валидацию
Тестирование на реальных данных, замер метрик (точность, полнота, время ответа), сбор обратной связи от пользователей.
Масштабируйте
Переход в продакшен: мониторинг, алерты, процедуры обновления модели, регламент обработки инцидентов, документация.
Практический совет: не пытайтесь спроектировать идеальную архитектуру до первого запуска. Сначала покажите, что модель решает задачу — потом масштабируйте.
Типовые ошибки при внедрении
Начинать с самой большой модели
8B-модель часто справляется не хуже 70B. Проверьте гипотезу на малом — потом масштабируйте.
Выбирать по бенчмаркам, а не по задаче
MMLU и HumanEval не покажут, как модель справится с суммаризацией ваших договоров на русском.
Игнорировать ИБ на старте
Согласуйте архитектуру с ИБ-службой до развёртывания, а не после первого аудита.
Недооценивать эксплуатацию
GPU потребляют ~300 Вт, модели нужно обновлять, сервис требует мониторинга. Закладывайте OpEx.
Не планировать замену моделей
Архитектура должна позволять менять модель без переписывания интеграций. OpenAI-совместимый API решает это.
Путать пилот с продакшеном
Ноутбук с RTX 4090 — это проверка гипотезы. Продакшен — сервер с резервированием, SLA и мониторингом.
С чего начинать
Развёртывание LLM в закрытом контуре — реалистичная задача для организации с профильными ИТ-компетенциями. Но это инженерный проект, а не покупка «коробочного решения».
Наиболее реалистичный путь: выберите одну конкретную задачу с измеримым результатом. Возьмите модель 7–8B (Llama 3.x или Qwen 3.x) в INT4. Разверните vLLM на сервере с GPU уровня RTX 4090 или A10G. Подключите к реальному процессу. Замерьте результат. И только после подтверждения гипотезы — масштабируйте.
Хотите развернуть LLM на своей инфраструктуре? AZONE AI реализует полный цикл: подбор железа, выбор и дообучение модели, интеграция с корпоративными системами — под ключ.
Решения AZONE-AI по теме
AzoneDoc
Готовое решение для корпоративного архива с on-premise LLM. Быстрый пилот, интеграция с 1С, SAP, ELMA.
Подробнее о продукте Юридическая аналитикаContractGuard
LLM в закрытом контуре для compliance-анализа договоров. On-premise, дообучение на данных заказчика.
Подробнее о продуктеТехнический документ: Архитектура внедрения LLM в закрытом контуре КИИ
PDF ~20 страниц для CISO и архитекторов. Регуляторный контекст, эталонная архитектура, чек-лист готовности к пилоту.
Начните с пилотного проекта
За 4–8 недель мы развернём решение на вашей инфраструктуре.
Обсудить пилот