Зашумить, чтобы защитить: можно ли маскировать персональные данные в запросах к нейросетям
Защита персональных данных при работе с LLM: prompt perturbation, дифференциальная приватность, регулярки, on-premise — и честный разбор того, что из этого реально работает

Юрист берёт абзац из клиентского договора и вставляет в ChatGPT, чтобы быстрее набросать ответ контрагенту. Ничего криминального — просто экономит сорок минут. Но вместе с текстом наружу уходят фамилии, суммы и реквизиты: персональные данные третьих лиц попадают во внешний сервис, чьи логи, политики хранения и юрисдикцию компания не контролирует. Такое в любой крупной организации происходит ежедневно и не по злому умыслу — просто по привычке.
Реакция служб безопасности обычно бывает двух видов. Жёсткий запрет внешних LLM — который сотрудники всё равно обходят с личных устройств. Или поиск технического компромисса: модели не запрещать, но перед отправкой наружу очищать запросы от чувствительных данных. Именно второй путь породил интерес к технике, которую в свежих научных работах называют prompt perturbation — подмена чувствительных фрагментов в тексте запроса до того, как он уйдёт в модель. Это лишь один из подходов внутри более широкой темы privacy-preserving inference, но именно он сейчас вызывает больше всего вопросов у практиков.
Разберём, что за этим стоит: какие техники работают, где они снижают риски, а где создают лишь иллюзию защиты. И где проходит граница, за которой ни один фильтр уже не поможет и единственный взвешенный ответ — локальное развёртывание модели.
Почему публичные LLM превратились в канал утечки данных
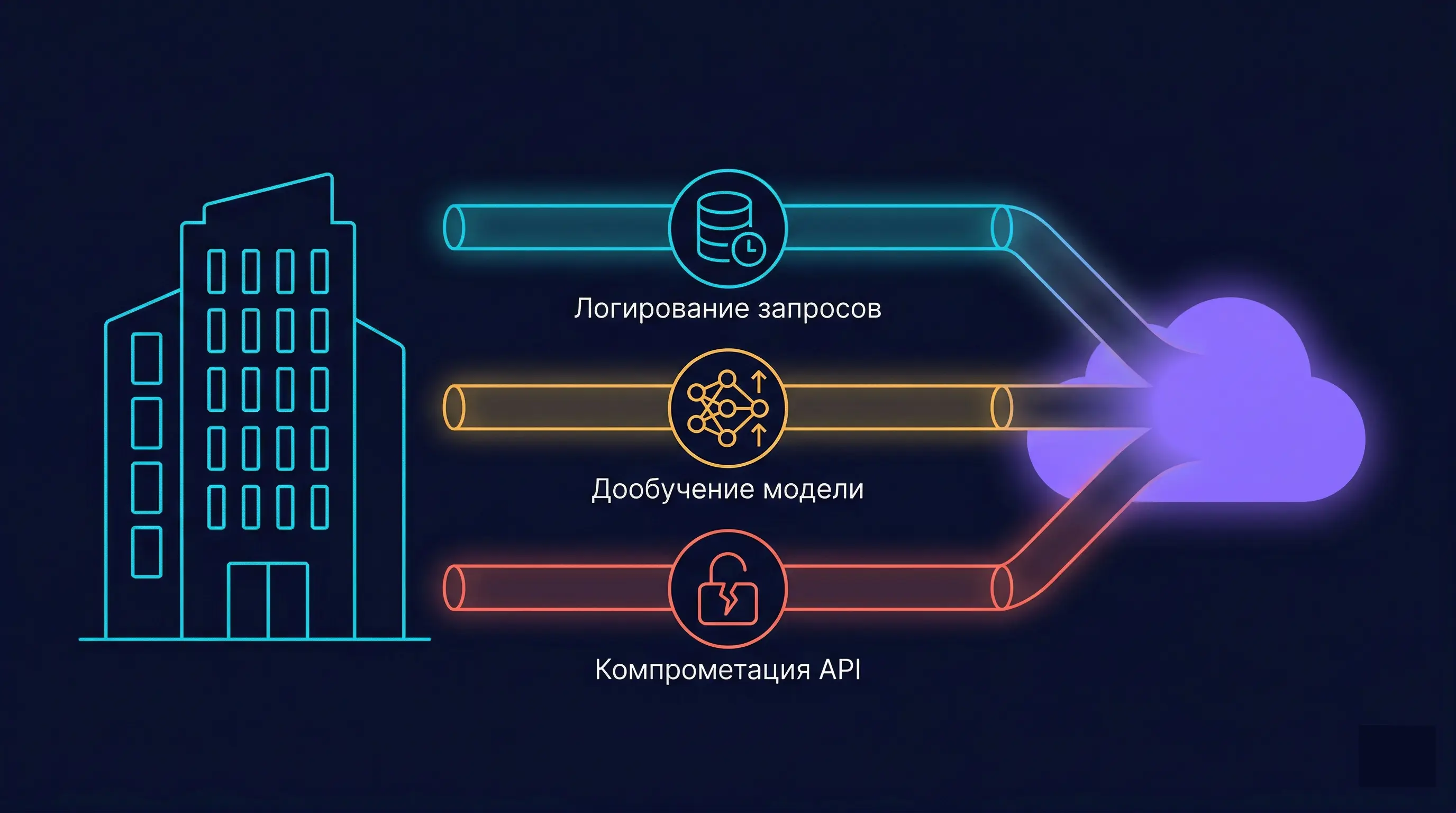
Классическая модель угроз в ИБ строится вокруг злоумышленника — внешнего или внутреннего. С публичными LLM всё иначе: данные чаще всего утекают через своего же сотрудника, который не пытается навредить, а просто хочет быстрее закрыть задачу.
Рисков здесь несколько, и все они архитектурные, а не поведенческие.
Даже если в политике провайдера написано, что запросы не используются для обучения, логи всё равно где-то хранятся и кому-то доступны. Отсутствие обучения не означает отсутствия хранения.
Пользовательские данные могут использоваться для дообучения, если организация не заключила отдельного соглашения. Далеко не все тарифы такое соглашение вообще допускают.
Промпт, ушедший наружу, живёт уже не только у исходного получателя. Любая утечка токенов или прокси-сервера превращает в утечку весь поток запросов.
Особенность LLM. Языковые модели отлично извлекают смысл из косвенных признаков. Для идентификации субъекта не нужно, чтобы в тексте стояло «Иванов Иван Иванович, 1978 г.р.». Достаточно уникального сочетания должности, отдела и региона — и человек определяется однозначно. Поэтому задача «вычистить» промпт простым поиском по шаблонам оказывается гораздо сложнее, чем выглядит.
Пять терминов, которые не стоит путать
В корпоративных политиках слова «маскирование», «обезличивание» и «зашумление» регулярно употребляют как синонимы. Это опасно: за каждым из них стоит своя техническая и юридическая конструкция.
Удаление и маскирование. Имена, телефоны и адреса вырезаются или заменяются на звёздочки. Просто, но модель теряет контекст, а иногда и вовсе выдумывает то, чего не было.
Замена идентификаторов на устойчивые псевдонимы с возможностью обратного сопоставления. Юридически это по-прежнему обработка персональных данных: пока существует ключ — данные не анонимны.
Преобразование, после которого личность субъекта нельзя восстановить даже теоретически. Для свободного текста задача куда сложнее, чем кажется: косвенные идентификаторы почти всегда остаются.
Математическая гарантия: результат обработки не должен заметно меняться от того, присутствует ли в исходном наборе конкретный человек. Параметр ε задаёт «бюджет приватности».
Чувствительные токены в запросе заменяются на правдоподобные подмены до отправки в модель, а при получении ответа выполняется обратная подстановка. Это не обезличивание и не дифференциальная приватность в строгом смысле — хотя современные разработки стараются объединить подмену токенов с математическими гарантиями приватности.
Как работает зашумление промпта
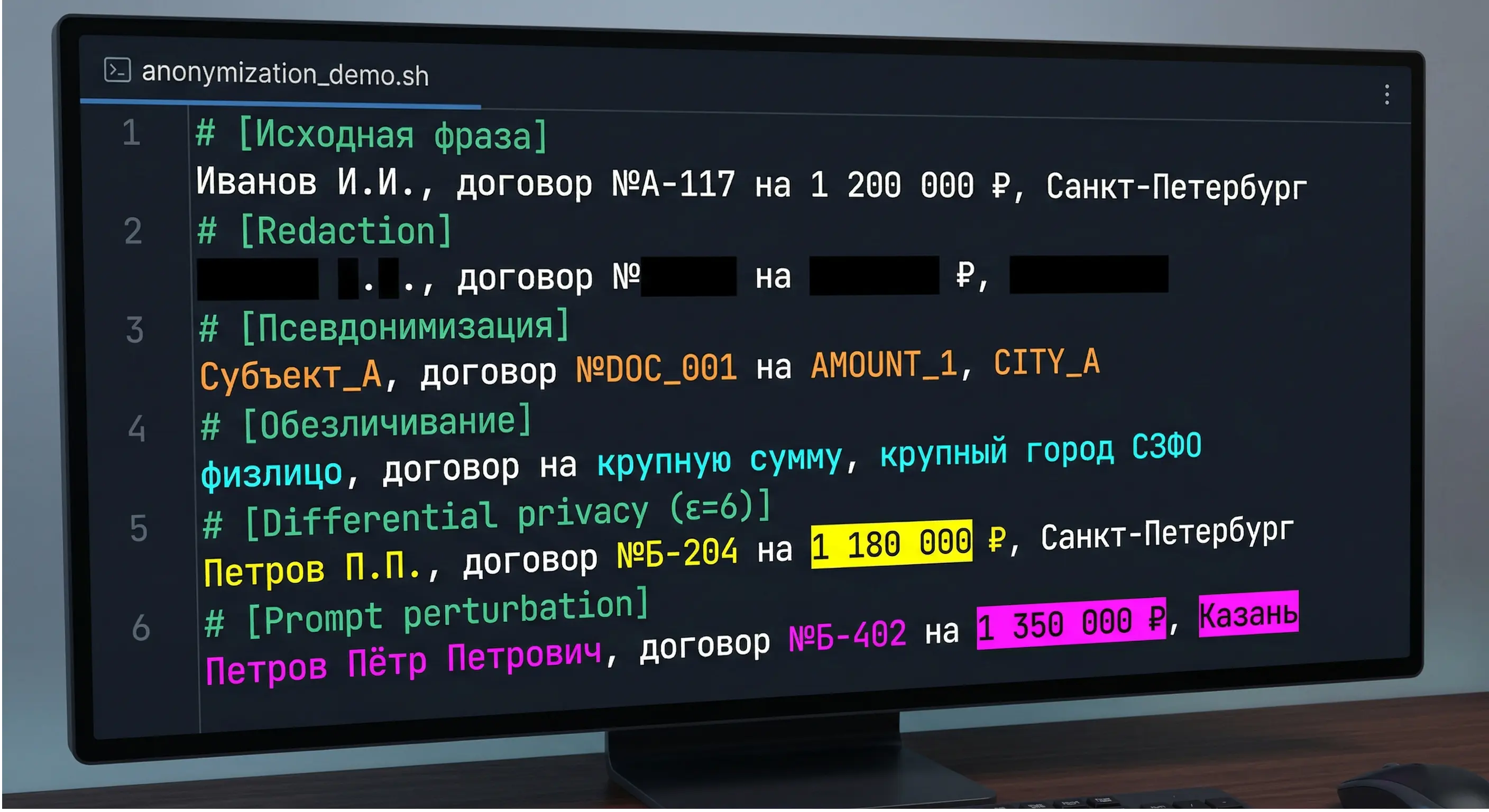
Идея кажется простой. Перед отправкой запроса во внешнюю модель локальный фильтр проходит по тексту, находит чувствительные сущности — имена, даты, номера документов, суммы, топонимы — и заменяет их на подмены. «Иванов Иван Иванович, Санкт-Петербург, договор №А-2024/117» превращается во что-то вроде «Петров Пётр Петрович, Казань, договор №Б-2023/402». Смысл запроса сохраняется: модель видит связный текст о человеке, городе и договоре. А конкретные значения из этого текста уже не восстановить.
Принципиальное отличие такой замены от грубого удаления в том, что модель получает грамматически и семантически полноценный контекст. Она не пытается угадать, что было на месте звёздочек, а работает с правдоподобной заготовкой. На стороне клиента при этом хранится словарь соответствий, по которому ответ модели возвращается к исходному виду — подмены в сгенерированном тексте заменяются обратно на настоящие значения.
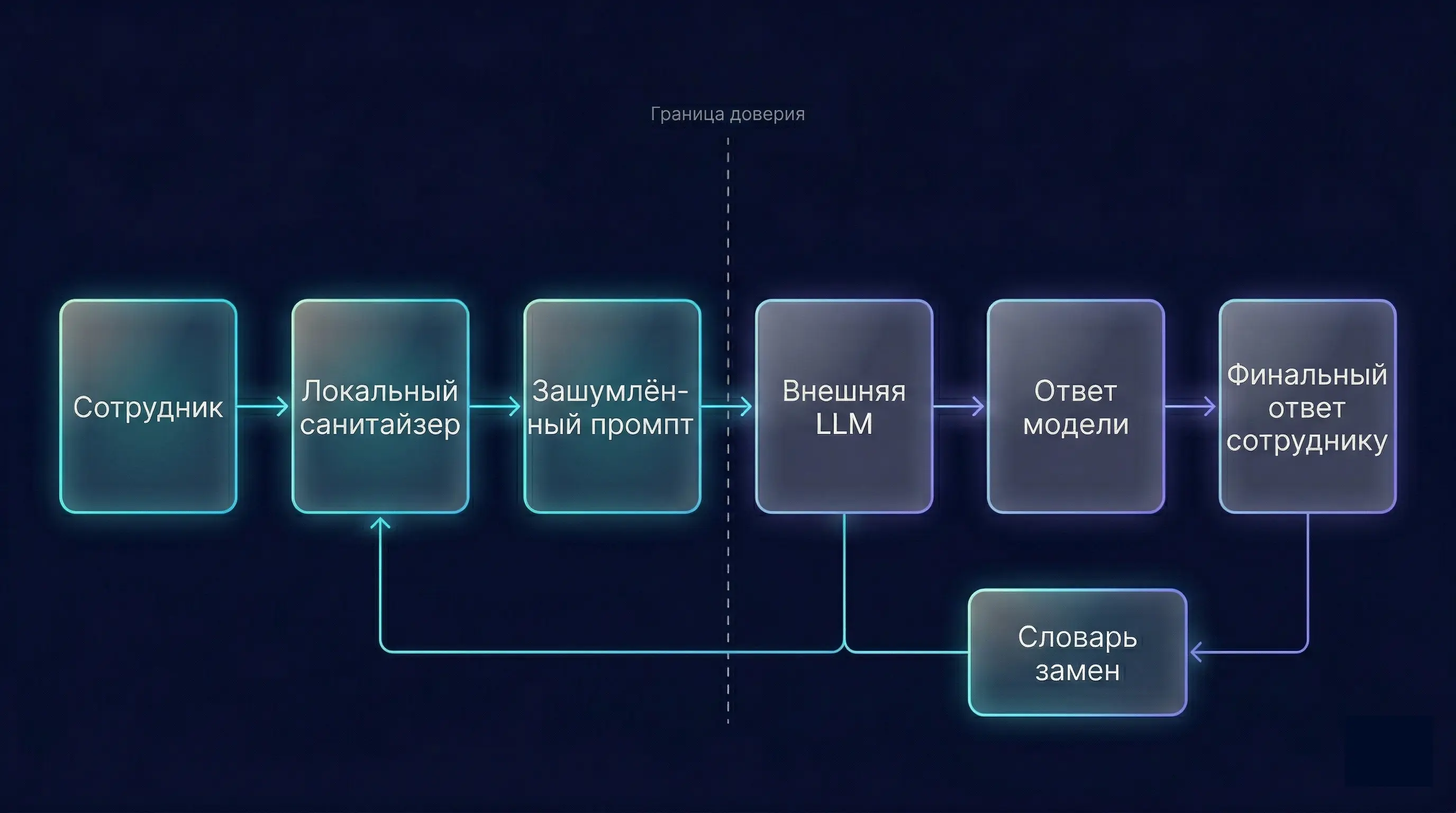
Техническая сложность начинается там, где регулярных выражений уже недостаточно. Сущности сначала надо найти — для этого нужна NER-модель, и её качество напрямую определяет качество защиты: пропущенная фамилия утечёт. Дальше подмены должны быть согласованы между собой. Если в тексте упоминается «Иванов» и местоимение «он», обе отсылки должны замениться так, чтобы модель по-прежнему понимала, что речь об одном человеке. И наконец, значение подмены влияет на ответ: если «сумму 1 200 000 рублей» заменить на «сумму 15 рублей», модель сочтёт ситуацию несущественной и выдаст бесполезный черновик.
Что предлагают исследователи: InferDPT в двух словах
Одна из самых содержательных работ последних лет на эту тему — InferDPT: Privacy-Preserving Inference for Black-box Large Language Model (Tong et al., 2023–2025). Авторы позиционируют её как первый практичный фреймворк для приватного инференса моделей, к которым у пользователя нет доступа изнутри — то есть именно для сценария «мы обращаемся к внешнему API».
Применяет к промпту экспоненциальный механизм дифференциальной приватности. Токены заменяются на другие с вероятностью, зависящей от семантической близости. Бюджет приватности ε регулирует, насколько итоговый промпт отходит от исходного.
Решает обратную задачу — из ответа на изменённый промпт нужно получить связный и осмысленный текст, соответствующий исходному запросу. По словам авторов, модуль вдохновлён идеями дистилляции знаний.
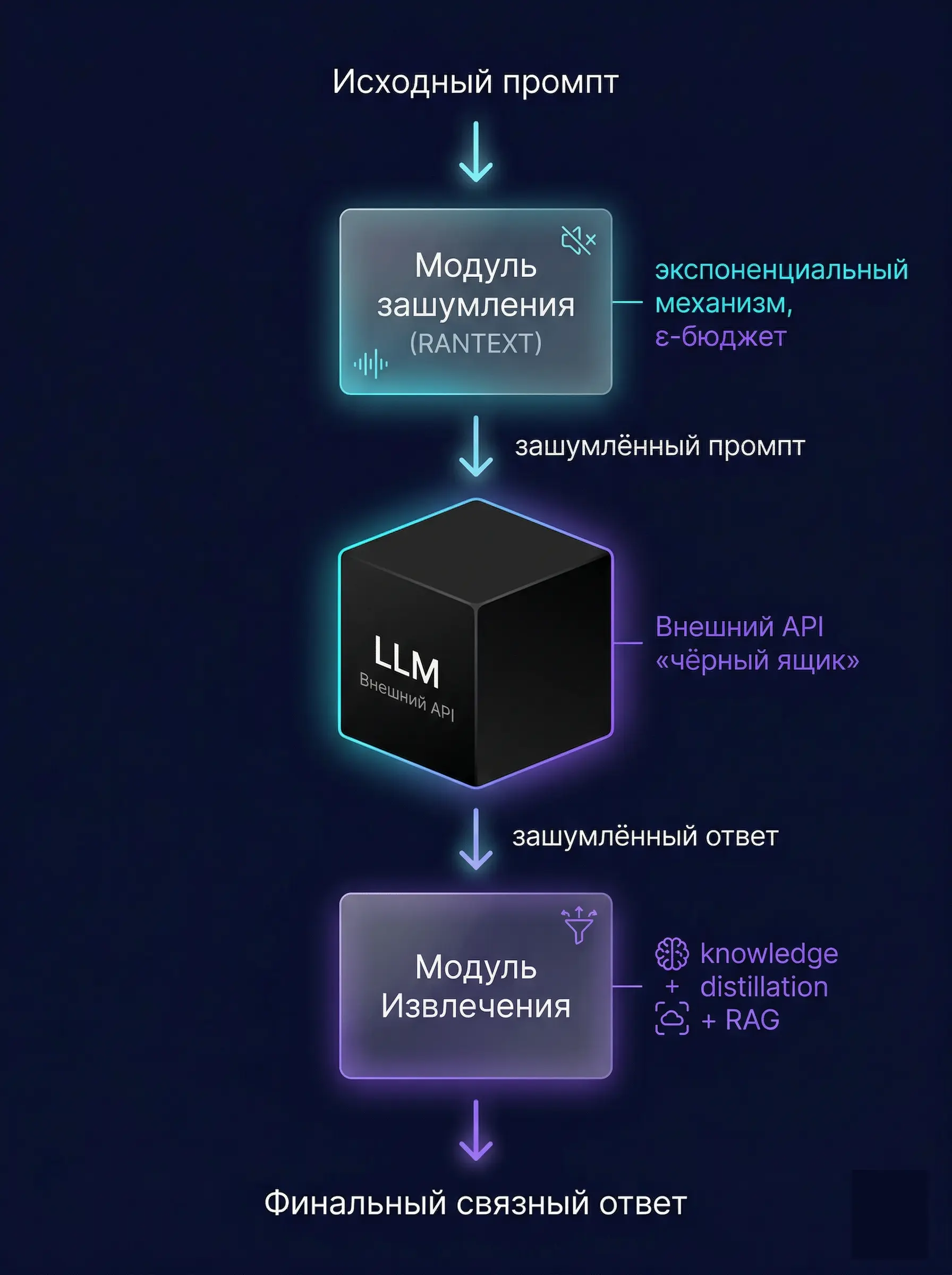
Отдельно авторы вводят механизм RANTEXT, рассчитанный на защиту от атак, которые пытаются восстановить исходные токены по эмбеддингам. По их экспериментам, при ε = 6,0 RANTEXT защищает от таких атак более чем в 90% случаев, а качество генерации остаётся сопоставимым с обычным GPT-4 без механизмов приватности.
Важная оговорка. Это цифры, полученные авторами на их собственных бенчмарках. К ним стоит относиться как к ориентиру, а не как к универсальной гарантии защищённости в любых сценариях.
Чем эта работа интересна практику, даже если внедрять InferDPT буквально никто не собирается? Она показывает, что между наивным маскированием и полноценным on-premise развёртыванием лежит целый спектр математически обоснованных решений. Регулярные выражения и словари замен тоже работают, но у них нет доказуемой гарантии приватности. Нет параметра, через который можно управлять тем, сколько информации утекает. У InferDPT такой параметр есть — это ε. Именно через него можно осознанно балансировать между защитой данных и качеством ответа модели, а не настраивать это на глазок.
Где зашумление реально снижает риск
Лучше всего оно работает там, где задача модели достаточно шаблонная, а чувствительные данные играют роль наполнителя, не сути запроса.
Первичная классификация жалоб, определение категории заявления, подготовка черновика ответа. Конкретная фамилия заявителя модели не нужна — нужен тип проблемы и тон обращения.
HR-бот, отвечающий на вопросы сотрудников по внутренним политикам. Юридический помощник, подсказывающий тип договора. Зашумление даёт возможность пользоваться мощными внешними моделями, не передавая имён реальных людей.
Маршрутизация обращений, извлечение ключевых параметров, суммаризация длинных переписок. Типовой сценарий, где потеря точных значений почти не влияет на качество решения.
Применимо, но только как один из слоёв защиты, не единственный. Для таких данных архитектурный ответ почти всегда — локальное развёртывание модели, а очистка промптов становится дополнительной мерой внутри контура.
Где подход ломается
У зашумления есть системные ограничения, про которые в маркетинговых материалах обычно молчат.
Чем агрессивнее фильтрация, тем хуже модель понимает запрос. На задачах, где нужно рассуждать над конкретными числами или датами, — эффект критичен. Юрист, получивший черновик на основе «суммы 15 рублей» вместо настоящей, быстро перестанет пользоваться таким инструментом.
Если фильтр неверно разобрался с кореференциями, модель перестаёт понимать, кто есть кто. Два упоминания одного человека превращаются в двух разных, и ответ получается бессмысленным.
Простая замена обратима, если злоумышленник получит доступ к словарю соответствий. А этот словарь где-то хранится — и это «где-то» само становится критичным активом, который нужно защищать.
Даже идеально зашумлённый промпт не скрывает, что ваша компания обратилась к внешнему сервису с запросом определённого типа. Для некоторых моделей угроз это уже чувствительная информация.
Его надо разрабатывать, поддерживать, обновлять под новые типы данных, тестировать на устойчивость к обходам. Ошибка в нём означает утечку, которую никто не заметит.
Зашумление промпта не превращает данные в обезличенные в смысле закона. Пока существует словарь обратной подстановки, это псевдонимизация, и требования к обработке персональных данных продолжают действовать в полном объёме.
Что делать на практике: трёхуровневая лестница
Если спуститься с теории на землю и говорить о том, что действительно внедряется в российских компаниях, получается трёхуровневая лестница.
Политики использования внешних LLM, DLP-правила, контролирующие содержимое промптов на корпоративных устройствах, простые фильтры по регулярным выражениям на очевидные паттерны — телефоны, СНИЛС, номера карт. Это не защита, а гигиенический минимум, но и его во многих компаниях пока нет.
Собственный сервис-фильтр с NER-моделью, обученной на русскоязычных текстах и доменной лексике компании. Согласованные по кореференциям словари замен. Аудит и логирование всех промптов, уходящих наружу. На этом этапе уже имеет смысл говорить о дифференциально-приватных механизмах в духе InferDPT — если есть команда, способная их сопровождать.
Для данных, которые нельзя отдавать наружу в принципе, честный ответ один: локальное развёртывание LLM в закрытом контуре. Современные открытые модели покрывают значительную часть корпоративных сценариев без обращения к внешним API вообще. Очистка при этом никуда не исчезает — она меняет роль и превращается из защитного барьера в инструмент минимизации данных внутри контролируемого периметра.
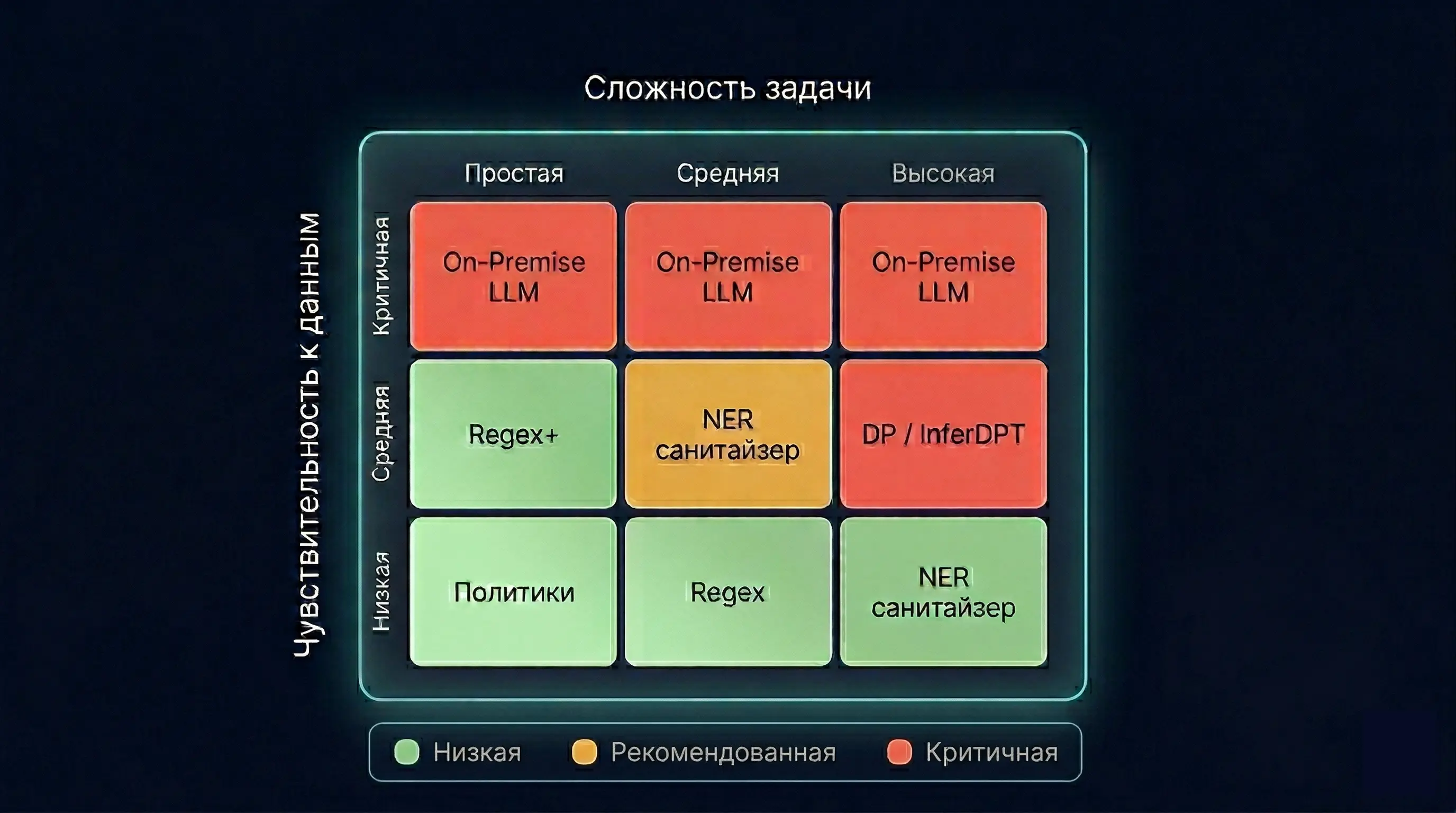
Принцип выбора. Граница между уровнями проходит по чувствительности данных и модели угроз, а не по размеру бизнеса. Стартап, работающий с медицинскими записями, обязан думать про on-premise с первого дня. Крупный ритейл, использующий LLM для суммаризации отзывов, обойдётся грамотной очисткой промптов.
Вывод
Зашумление запросов — полезный инструмент, который заслуживает места в арсенале корпоративной защиты данных. Оно позволяет пользоваться мощью публичных LLM там, где полный запрет избыточен, а полное доверие — наивно. Работы вроде InferDPT показывают, что этот подход можно делать математически строгим, а не интуитивным.
При этом важно не обманываться: никакая техника замены токенов не превращает передачу данных во внешний сервис в «отсутствие передачи». Риск снижается, но не исчезает. Задача злоумышленника усложняется, но остаётся выполнимой. А требования закона о персональных данных продолжают действовать вне зависимости от того, насколько умно вы подменили фамилии в промпте.
Зашумление — это один из слоёв защиты, не более. Его применяют осознанно и только там, где баланс между приватностью и полезностью просчитан. Для всего остального остаётся самый надёжный способ не отдать данные наружу — не отправлять их наружу вовсе.
AZONE AI помогает компаниям выстраивать работу с LLM там, где данные не должны покидать периметр: от очистки промптов до развёртывания моделей в закрытом контуре с учётом требований ФСТЭК и ФСБ. Если вы оцениваете, какой уровень защиты подходит вашим сценариям — оставьте заявку на консультацию.
Актуальность материала
- Материал подготовлен по состоянию на апрель 2026 года.
- Ссылка на работу InferDPT (Tong et al.) указывает на arXiv-версию статьи от марта 2025 года, rev. v7.
- Рекомендации по внедрению носят общий характер. Перед выбором подхода защиты рекомендуем провести оценку рисков на ваших данных и модели угроз.
Защитите данные до того, как они уйдут
За 4–8 недель мы спроектируем архитектуру работы с LLM под вашу модель угроз и развернём решение в закрытом контуре.
Обсудить пилот