ИИ в информационной безопасности: 7 практических сценариев
Как нейросети усиливают SIEM, DLP и SOAR — конкретные кейсы автоматизации для ИБ‑подразделений
Средний SOC в крупной российской компании обрабатывает десятки тысяч событий безопасности в сутки. Из них реальную угрозу представляют единицы. Остальное — шум: легитимные аномалии, ошибки конфигурации, дублирующиеся алерты, ложные срабатывания DLP на документах с ключевыми словами, но без реального риска утечки. Аналитик первой линии физически не способен качественно разобрать каждое событие — и это не вопрос квалификации. Это вопрос масштаба.
Параллельно растёт сложность атак, увеличивается площадь защиты (облака, удалёнка, IoT, подрядчики), а дефицит специалистов по ИБ никуда не делся. В этих условиях искусственный интеллект — не модная добавка к инфраструктуре безопасности, а рабочий инструмент, который позволяет команде заниматься тем, что действительно требует человеческого мышления.
В этой статье — семь прикладных сценариев, где ИИ уже приносит измеримую пользу ИБ-подразделениям. Без восторженных обещаний, но с честным разбором ограничений.

Почему автоматизация ИБ с помощью ИИ — вопрос сейчас, а не «когда‑нибудь»
Проблема перегрузки SOC не нова, но за последние два-три года она перешла из категории «неудобство» в категорию «системный риск». Несколько факторов сошлись одновременно.
Во-первых, количество источников событий выросло кратно. Если пять лет назад SIEM собирал логи с периметра, AD и нескольких серверов, то сегодня в контур попадают облачные сервисы, контейнерные среды, endpoint-агенты, сетевые сенсоры, DLP-системы, средства контроля привилегированного доступа и десятки других источников. Каждый из них генерирует поток событий, а корреляционные правила, написанные вручную, не успевают за изменениями в инфраструктуре.
Во-вторых, злоумышленники адаптируются быстрее, чем обновляются сигнатуры. Фишинговые кампании стали точечными, lateral movement — медленным и малозаметным, а социальная инженерия использует контекст, который невозможно отловить статическим правилом.
В-третьих, рынок кадров не успевает за спросом. Найти опытного аналитика SOC, который умеет работать с конкретной SIEM-платформой, понимает сетевую инфраструктуру заказчика и способен принимать решения под давлением — задача, на которую уходят месяцы. А удерживать таких специалистов, когда рутинная нагрузка на них растёт каждый квартал, ещё сложнее.
ИИ не решает все эти проблемы разом. Но он позволяет перераспределить нагрузку: забрать у аналитика монотонную, повторяющуюся работу и дать ему возможность заниматься задачами, где нужны опыт, контекст и суждение.
Что ИИ меняет в работе SOC: ML, LLM и модели классификации
Обучаются на исторических данных и выявляют паттерны, которые сложно описать правилами. Это основа UEBA, anomaly detection и поведенческого анализа.
Обрабатывают неструктурированный текст: логи, тикеты, отчёты, письма, playbook'и. Умеют суммаризировать, классифицировать, генерировать черновики и отвечать на вопросы по контексту.
Обучены на конкретных задачах: определение типа атаки, оценка критичности инцидента, детектирование фишинга по совокупности признаков.
Важно понимать: ни одна из этих технологий не является «кнопкой безопасности». Каждая требует качественных данных, настройки, валидации и обязательно контроля со стороны человека. ИИ в ИБ — это усилитель аналитика, а не его замена.
7 сценариев применения ИИ в ИБ
Сценарий 1. ML-приоритизация и обогащение алертов в SIEM
Где используется
В SOC на этапе первичной обработки потока алертов из SIEM-системы — до того, как событие попадает к аналитику.
Какую задачу решает
Типичная SIEM генерирует сотни и тысячи алертов в день. Большинство из них — low или medium severity по формальным критериям, но среди них встречаются события, которые в контексте конкретной инфраструктуры являются критическими. Ручная приоритизация — это или слишком медленно, или слишком грубо.
Как работает на практике
ML-модель обучается на исторических данных: какие алерты приводили к реальным инцидентам, какие закрывались как false positive, какие требовали эскалации. На вход модель получает не только параметры самого алерта, но и контекст — информацию об активе (его критичность, владелец, сегмент сети), данные из threat intelligence-фидов, историю предыдущих алертов по этому источнику.
На выходе — скорректированный приоритет и обогащённая карточка алерта, в которой аналитик сразу видит, почему модель оценила событие как значимое. В типовом сценарии внедрения это позволяет сократить объём ручной обработки алертов первой линией и быстрее выводить критичные события на вторую-третью линию.
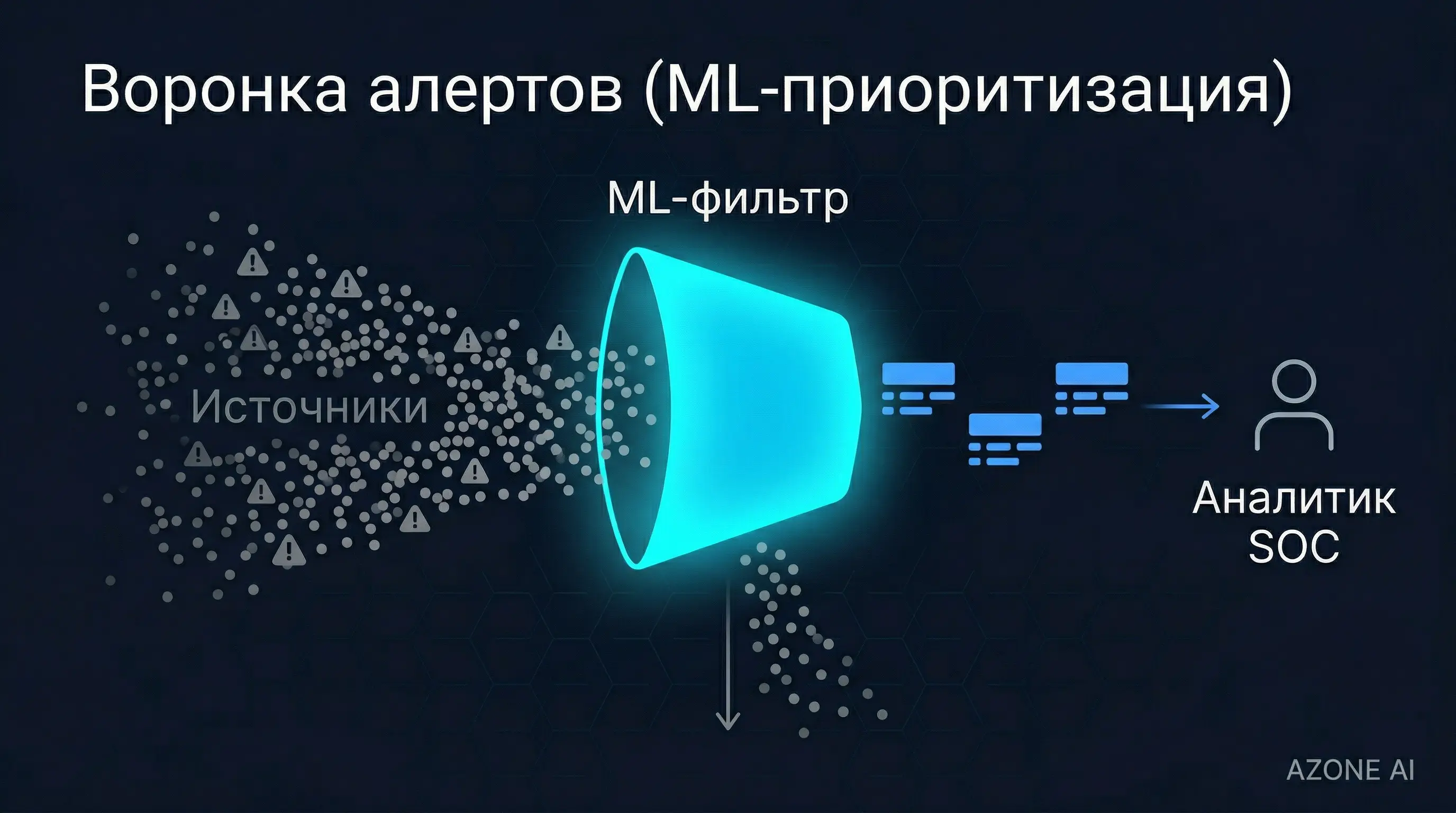
Воронка: поток событий → ML-фильтр → обогащённые алерты → аналитик SOC
В чём выигрыш. Аналитик тратит меньше времени на очевидный шум и получает предварительно обогащённый контекст. Время реакции на реальные угрозы сокращается. Меньше вероятность пропустить критичное событие, «утонувшее» в потоке low-severity алертов.
Ограничения. Качество модели напрямую зависит от качества исторических данных. Если инциденты исторически размечались небрежно, модель унаследует эти ошибки. Кроме того, модель не понимает бизнес-контекст, который известен только команде ИБ: например, что конкретный сервер на этой неделе участвует в миграции и его поведение ожидаемо аномально.
Где нужен контроль человека. Финальное решение об эскалации остаётся за аналитиком. Модель предлагает приоритет — человек его подтверждает, корректирует или отклоняет. Регулярный аудит решений модели необходим, чтобы отслеживать дрейф качества.
Сценарий 2. Автоматический triage инцидентов в SOC с помощью ИИ
Где используется
На стыке SIEM и IRP/SOAR — в момент, когда алерт превращается в инцидент и требует классификации, назначения ответственного и определения первоочередных действий.
Какую задачу решает
Triage — одна из самых трудоёмких и при этом рутинных операций в SOC. Аналитик должен определить тип инцидента, его потенциальный масштаб, затронутые активы, применимый playbook и приоритет обработки. На это уходят минуты, которые при массовом потоке инцидентов превращаются в часы.
Как работает на практике
Модель классификации получает набор признаков инцидента: тип алерта, источник, затронутые хосты, учётные записи, время, последовательность событий. На основе обучения на размеченном корпусе предыдущих инцидентов она предлагает: категорию (malware, unauthorized access, data exfiltration, policy violation и т. д.), рекомендуемый playbook, предварительную оценку severity и список первоочередных действий.
В типовом сценарии автоматический triage покрывает значительную долю стандартных категорий инцидентов. Для нестандартных кейсов модель помечает инцидент как требующий ручной классификации — и это важная часть дизайна системы.
В чём выигрыш. Ускорение первичной обработки инцидентов. Стандартизация: одинаковые инциденты классифицируются одинаково, независимо от того, кто из аналитиков на смене. Снижение когнитивной нагрузки на L1-аналитиков.
Ограничения. Модель плохо справляется с инцидентами, которые не похожи на исторические. Атаки нового типа, сложные цепочки событий, инциденты на стыке нескольких систем — всё это требует человеческого анализа. Кроме того, ошибка в автоматическом triage может привести к неправильному playbook'у и потере времени.
Где нужен контроль человека. Аналитик должен иметь возможность легко переопределить решение модели. Для инцидентов высокой критичности автоматический triage лучше использовать как подсказку, а не как финальное решение. Обязателен периодический ретроспективный анализ: совпали ли автоматические классификации с реальным ходом расследований.
Сценарий 3. UEBA: выявление аномального поведения пользователей и устройств на основе ML
Где используется
В системах класса UEBA, а также в расширенных модулях SIEM, EDR и NTA, которые анализируют поведение учётных записей, рабочих станций, серверов и сетевых сегментов.
Какую задачу решает
Статические правила ловят известные паттерны: вход в нерабочее время, обращение к запрещённому ресурсу, превышение объёма скачанных данных. Но целый класс угроз — компрометация учётных записей, инсайдерская активность, медленная эксфильтрация — выглядит как легитимная деятельность, если смотреть на каждое событие по отдельности. Аномалия проявляется только в совокупности и в отклонении от индивидуального профиля.
Как работает на практике
ML-модель строит поведенческий профиль для каждой сущности: пользователя, хоста, сервисной учётной записи. Профиль включает типичные паттерны: время активности, набор используемых ресурсов, объёмы передаваемых данных, географию подключений, последовательность действий. Отклонения от профиля формируют risk score — чем больше отклонений, чем они необычнее, тем выше балл.
Типовой сценарий: учётная запись сотрудника, которая обычно работает с тремя корпоративными системами в рабочее время, вдруг начинает обращаться к файловым хранилищам других департаментов поздно вечером. Каждое отдельное действие формально разрешено, но совокупность сигнализирует об аномалии.
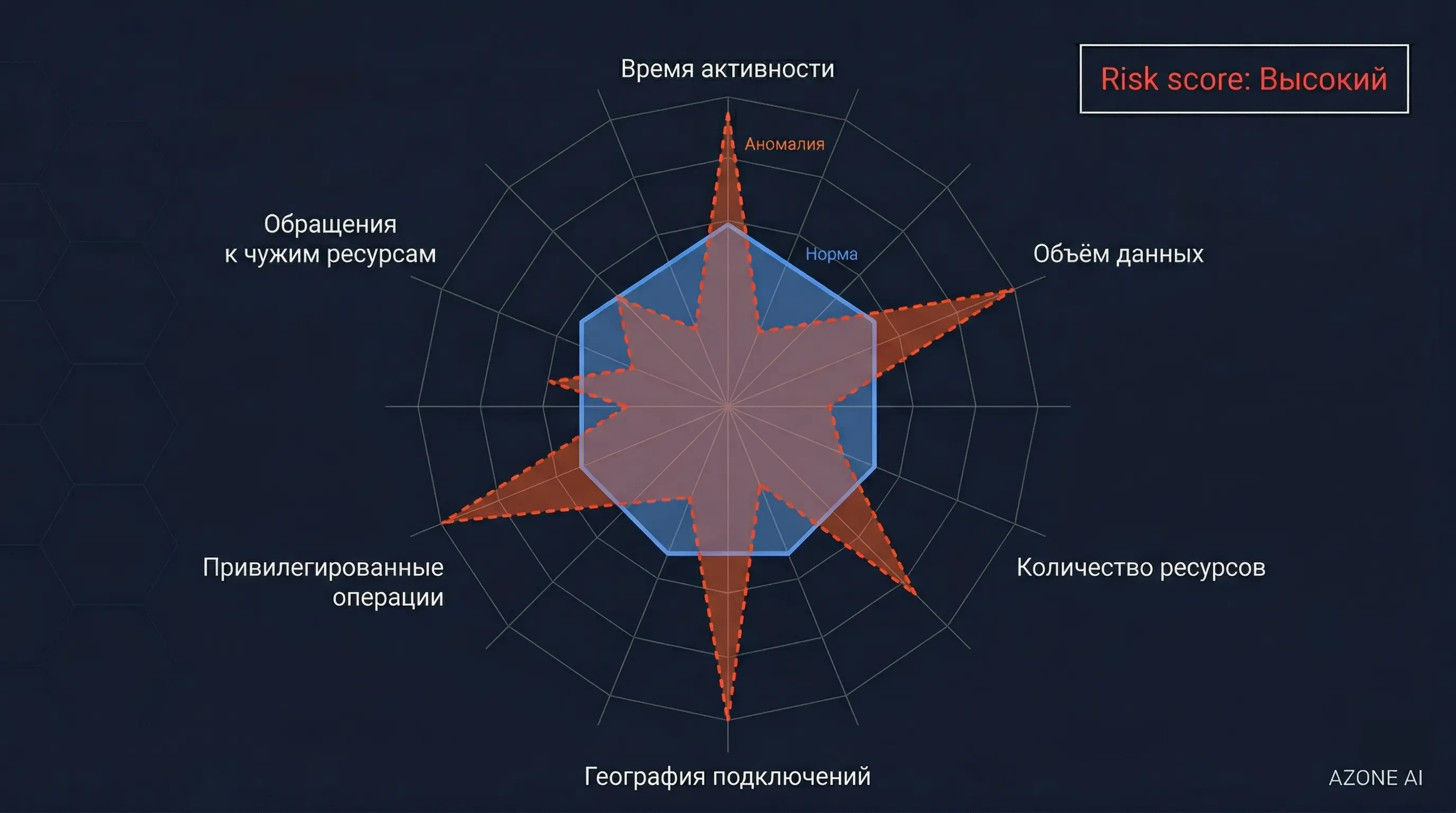
Радарный график: нормальный профиль (синий) vs аномальное поведение (красный)
В чём выигрыш. Обнаружение угроз, которые невозможно поймать правилами. Раннее выявление компрометации учётных записей. Возможность приоритизировать расследования по risk score, а не по потоку однотипных алертов.
Ограничения. UEBA на основе ML генерирует собственные ложные срабатывания — особенно в период обучения и при изменениях в бизнес-процессах (реорганизация, смена проектов, сезонные пики). Модель может «привыкнуть» к постепенно нарастающей аномалии, если та развивается достаточно медленно. Кроме того, качество профилей критически зависит от полноты источников данных: если часть активности пользователя не попадает в модель, профиль будет неполным.
Где нужен контроль человека. Интерпретация аномалий. Высокий risk score — это повод для расследования, а не доказательство инцидента. Аналитик должен оценить контекст: может быть, сотрудник перешёл в другой отдел, или это штатная активность в рамках проекта. Регулярная калибровка порогов и пересмотр базовых профилей — тоже задача для людей.
Сценарий 4. ИИ в DLP: снижение ложных срабатываний и интеллектуальный анализ событий
Где используется
В DLP-системах и смежных решениях, которые контролируют каналы передачи данных: электронную почту, мессенджеры, облачные хранилища, USB-устройства, печать.
Какую задачу решает
Классическая DLP работает по политикам: ключевые слова, регулярные выражения, цифровые отпечатки документов, метки конфиденциальности. Проблема в том, что такие политики неизбежно порождают огромное количество ложных срабатываний. Документ с упоминанием слова «конфиденциально» в шаблонном отказе от ответственности в подписи письма. Файл с номерами, похожими на паспортные данные, но на самом деле содержащий номера заказов. Отправка рабочих материалов контрагенту, согласованная с руководителем, но не описанная в исключениях DLP-политики.
Как работает на практике
Офицер ИБ, который ежедневно разбирает сотни таких событий, неизбежно теряет внимательность — и пропускает реальную утечку среди шума.
ML-модель анализирует событие DLP в контексте: не только содержимое перехваченного объекта, но и поведение отправителя (его типичные паттерны работы с данными), характер получателя (внутренний, внешний, новый, доверенный), историю аналогичных событий и их исходы. На основе совокупности признаков модель оценивает вероятность реального нарушения и ранжирует события.
В практике рынка это позволяет существенно сократить количество событий, которые требуют ручного разбора офицером ИБ, фокусируя его внимание на действительно подозрительных случаях.
В чём выигрыш. Снижение нагрузки на DLP-оператора. Меньше «алертной усталости» — значит, выше вероятность, что реальная утечка будет замечена. Возможность постепенно ужесточать DLP-политики без пропорционального роста ложных срабатываний.
Ограничения. Модель может ошибаться в обе стороны: пропустить реальную утечку (если паттерн не встречался в обучающей выборке) или заблокировать легитимную операцию. В контексте DLP ошибка второго типа может блокировать бизнес-процесс, а ошибка первого — стоить компании утечки. Кроме того, DLP-данные чувствительны по своей природе, и использование их для обучения моделей требует отдельного внимания к защите этих данных.
Где нужен контроль человека. Решение о блокировке передачи данных не должно приниматься моделью автономно — по крайней мере, до тех пор, пока модель не прошла длительную валидацию на конкретной инфраструктуре. Исключения из политик, работа с VIP-пользователями, обработка инцидентов с юридическими последствиями — всё это требует человеческого суждения.
Сценарий 5. Генерация playbook'ов в SOAR с помощью LLM
Где используется
В платформах оркестрации и автоматизации реагирования (SOAR), а также в IRP-системах, где определяются последовательности действий при различных типах инцидентов.
Какую задачу решает
Создание и поддержание playbook'ов — одна из тех задач, которые все признают важными, но на которые хронически не хватает времени. В результате playbook'и устаревают, не покрывают новые типы инцидентов, содержат шаги, которые уже нерелевантны для текущей инфраструктуры, или вовсе отсутствуют для целых категорий событий.
Как работает на практике
LLM-модель, имеющая доступ к документации по инфраструктуре, существующим playbook'ам, базе знаний SOC и истории инцидентов, может генерировать черновики playbook'ов для новых типов инцидентов. Модель анализирует: какие шаги предпринимались в аналогичных случаях, какие действия были эффективны, какие источники данных использовались, какие эскалации производились.
Кроме того, LLM может анализировать существующие playbook'и и предлагать оптимизации: убрать избыточные шаги, добавить недостающие проверки, привести формулировки к единому стандарту, выявить пробелы в покрытии.
Это типовой сценарий, который набирает популярность в зрелых SOC, где есть достаточный объём документированных процедур.
В чём выигрыш. Ускорение создания playbook'ов в разы. Снижение зависимости от одного-двух экспертов, которые «держат всё в голове». Единообразие документации. Возможность быстро адаптировать playbook'и при изменении инфраструктуры или появлении новых угроз.
Ограничения. LLM генерирует черновик, а не готовый к продуктиву документ. Модель может предложить шаги, которые невозможны в конкретной инфраструктуре, или пропустить специфику, которая известна только команде. «Галлюцинации» — генерация правдоподобных, но некорректных рекомендаций — реальный риск, особенно если модель не имеет актуального контекста об инфраструктуре.
Где нужен контроль человека. Каждый сгенерированный playbook должен проходить ревью опытного специалиста перед внедрением в продуктив. Автоматическое выполнение playbook'ов, сгенерированных ИИ без человеческой валидации, — недопустимо. Особенно это касается действий, которые могут повлиять на доступность сервисов: блокировка учётных записей, изоляция хостов, изменение сетевых правил.
Сценарий 6. Детектирование фишинга: анализ писем и вложений с помощью ИИ
Где используется
В системах защиты электронной почты, песочницах, антифишинговых модулях, а также при ручном разборе подозрительных сообщений, которые пересылают сотрудники.
Какую задачу решает
Фишинг остаётся вектором номер один для первоначальной компрометации. При этом современные фишинговые письма всё меньше похожи на нигерийских принцев — они персонализированы, стилистически грамотны, используют реальный контекст (имена коллег, текущие проекты, актуальные события). Статические фильтры и списки доменов не справляются с целевым фишингом.
Как работает на практике
Комбинация ML-классификатора и LLM-анализа позволяет оценить письмо с нескольких сторон. ML-модель анализирует технические признаки: заголовки, SPF/DKIM/DMARC, репутацию отправителя, URL-паттерны, характеристики вложений. LLM анализирует содержание: выявляет манипулятивные паттерны (urgency, authority, fear), проверяет логическую связность контекста, сравнивает стиль с предыдущими письмами предполагаемого отправителя.
В типовом сценарии при обработке писем, пересланных сотрудниками как подозрительные, такой анализ позволяет быстро дать заключение: фишинг с высокой вероятностью, легитимное письмо, требует ручного разбора. Это значительно ускоряет обработку обращений и снижает нагрузку на аналитиков.
В чём выигрыш. Сокращение времени на разбор подозрительных писем. Выявление сложных фишинговых кампаний, которые проходят через стандартные фильтры. Возможность автоматически формировать IOC (индикаторы компрометации) по результатам анализа и обогащать ими защитные системы.
Ограничения. LLM-анализ текста письма — ресурсоёмкая операция, которую нецелесообразно применять к каждому входящему письму. Обычно он используется как второй эшелон — для писем, которые прошли первичный фильтр, но вызвали подозрения. Кроме того, анализ вложений и URL всё ещё требует традиционных инструментов: песочниц, статических анализаторов, сервисов проверки репутации.
Где нужен контроль человека. Решение о блокировке домена, оповещении пользователей и запуске расследования принимает аналитик. Особенно важен человеческий контроль при анализе целевого фишинга (spear phishing): модель может не учитывать внутренний контекст — например, что «подозрительное» письмо на самом деле связано с текущей M&A-сделкой, о которой знает ограниченный круг лиц.
Сценарий 7. LLM-ассистент аналитика: суммаризация логов, гипотезы, отчёты
Где используется
На рабочем месте аналитика SOC — при расследовании инцидентов, подготовке отчётов, анализе логов и формировании рекомендаций.
Какую задачу решает
Расследование инцидента — это работа с большим объёмом разнородных данных: логи из нескольких систем, тикеты из IRP, данные из EDR, сетевые дампы, переписка, результаты сканирования. Аналитик тратит значительную часть времени не на анализ как таковой, а на сбор, структурирование и суммаризацию информации. А потом — на написание отчёта, который тоже требует времени и аккуратности.
Как работает на практике
LLM-ассистент, интегрированный в рабочую среду аналитика, помогает на нескольких этапах. На этапе сбора — суммаризирует большие объёмы логов, выделяя аномалии и значимые события. На этапе анализа — помогает формулировать гипотезы: «учитывая цепочку событий A → B → C, наиболее вероятный сценарий — компрометация через подрядчика». На этапе документирования — генерирует черновик отчёта об инциденте по заданной структуре, с хронологией, списком затронутых активов и рекомендациями.
Это условный пример внедрения, но направление активно развивается: ряд вендоров SIEM/SOAR уже включают LLM-ассистентов в свои платформы.
В чём выигрыш. Ускорение расследований. Стандартизация отчётности. Возможность для менее опытных аналитиков быстрее выходить на продуктивный уровень, используя ИИ-ассистента как «второе мнение». Снижение рутинной нагрузки на старших аналитиков.
Ограничения. LLM может генерировать правдоподобные, но ложные выводы — особенно при анализе сложных, многоэтапных инцидентов. Модель не имеет полного контекста о бизнес-процессах организации и может неверно интерпретировать легитимную активность. Суммаризация логов может упустить нюансы, которые критически важны для расследования.
Где нужен контроль человека. ИИ-ассистент — это инструмент, а не замена аналитика. Все гипотезы должны проверяться, все черновики отчётов — вычитываться, все рекомендации — валидироваться с учётом контекста, который модели недоступен. Особенно критично это для инцидентов с юридическими или регуляторными последствиями, где точность и обоснованность выводов имеют принципиальное значение.
Где нейросети полезны, а где их переоценивают
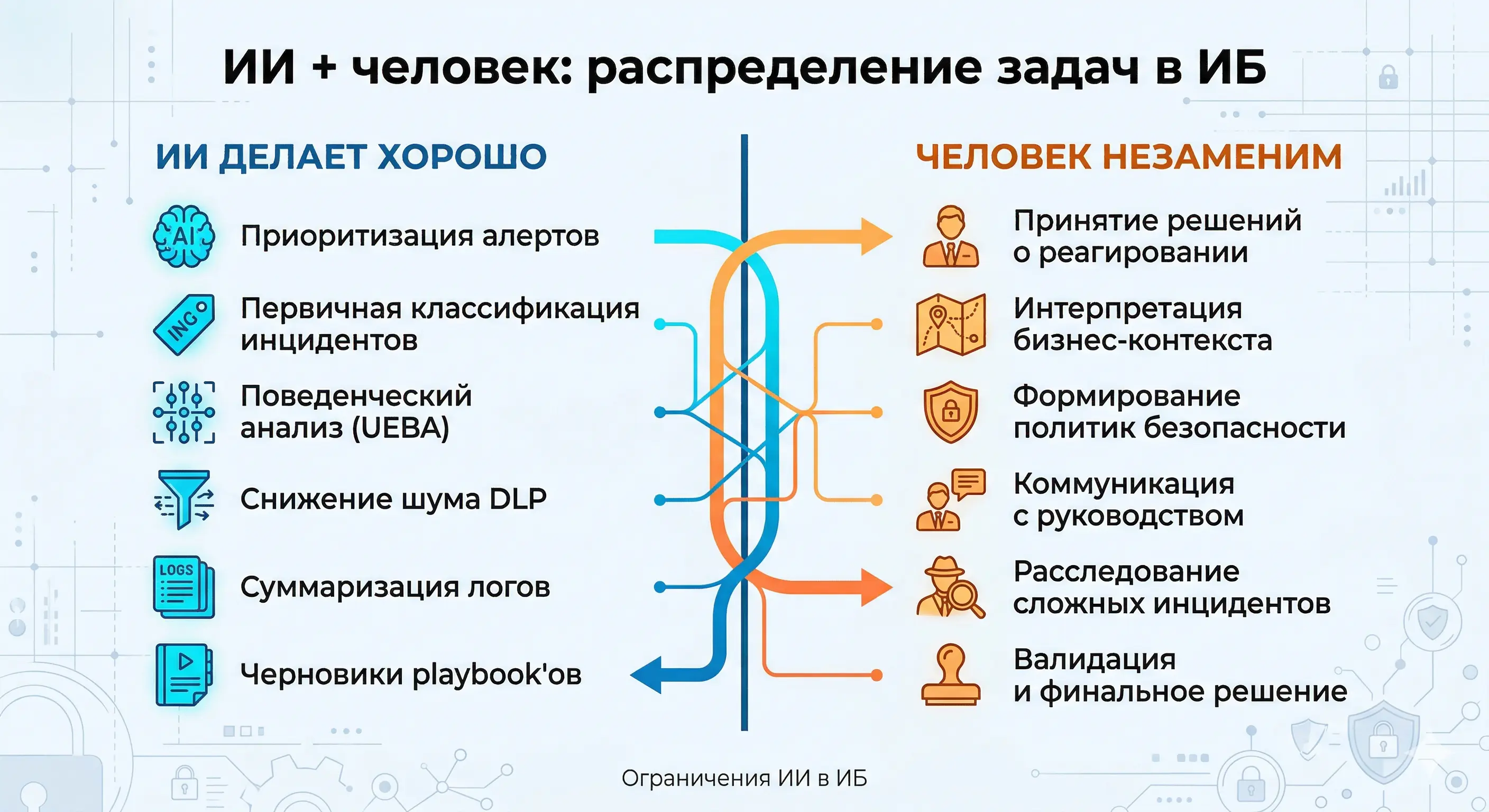
ИИ + человек: распределение задач в ИБ
ИИ полезен там, где есть большой объём однотипных задач, где важна скорость первичной обработки и где ошибка модели может быть быстро скорректирована человеком. Приоритизация алертов, triage, поведенческий анализ, суммаризация — всё это задачи, где ИИ даёт реальный выигрыш.
Переоценивают ИИ там, где требуется глубокое понимание контекста, стратегическое мышление и ответственность за последствия. Принятие решений о реагировании на инциденты высокой критичности, формирование политик безопасности, оценка бизнес-рисков, коммуникация с руководством и регуляторами — всё это остаётся задачей человека.
Несколько типичных заблуждений, которые стоит оставить за рамками ожиданий.
Не заменит. Изменит характер их работы — от разбора шума к анализу сложных кейсов. Но потребность в квалифицированных людях не снизится, а скорее вырастет, потому что кто-то должен управлять ИИ-инструментами, валидировать их результаты и обрабатывать то, с чем модель не справилась.
Не заработает. Любая ML-модель требует данных для обучения, интеграции с источниками событий, настройки порогов, калибровки и постоянной поддержки. Проект внедрения ИИ в ИБ — это именно проект, а не установка коробочного решения.
Скорее перераспределит. Экономия на рутинных операциях компенсируется затратами на внедрение, поддержку, обучение команды и вычислительные ресурсы. Реальная ценность — не в снижении бюджета, а в повышении эффективности команды при том же или растущем объёме угроз.
6 принципов внедрения ИИ в SOC
Несколько принципов, которые снижают риски разочарования и повышают шансы на реальный результат.
Начинайте с конкретной задачи, а не с технологии
Не «давайте внедрим ИИ в SOC», а «нам нужно сократить время triage с 15 минут до 3». Чёткая задача позволяет выбрать адекватный инструмент и измерить результат.
Обеспечьте качество данных
Это скучно, но критично. Если логи неполные, события не нормализованы, инциденты не размечены, а активы не классифицированы — модель не сможет обучиться. Инвестиции в data quality окупаются до внедрения ИИ, а после него — тем более.
Планируйте пилот, а не «большой взрыв»
Выберите один сценарий, один сегмент инфраструктуры, одну команду. Проведите пилот с чёткими критериями успеха. Масштабируйте только после того, как подтвердите результат.
Учитывайте требования к защите данных
ИИ-модели обрабатывают чувствительные данные: логи, содержание писем, поведение пользователей. Облачные LLM-сервисы могут быть неприемлемы для организаций с жёсткими требованиями к защите информации. В таких случаях стоит рассматривать on-premise развёртывание или решения, которые работают в закрытом контуре.
Инвестируйте в команду
ИИ-инструменты требуют людей, которые умеют с ними работать: настраивать, валидировать, интерпретировать результаты. Это не обязательно data scientist'ы — но аналитики ИБ, которые понимают принципы работы моделей и умеют критически оценивать их выводы.
Выстраивайте процесс обратной связи
Модели деградируют, если их не поддерживать. Результаты работы ИИ должны регулярно оцениваться, ошибки — анализироваться, а модели — дообучаться или перенастраиваться. Без замкнутого цикла обратной связи любой ИИ-проект со временем теряет эффективность.

Чеклист внедрения — можно сохранить и переслать коллегам
Заключение
ИИ в информационной безопасности — это не революция, а эволюция. Инструменты, которые позволяют делать больше с тем же ресурсом, реагировать быстрее, замечать то, что раньше терялось в шуме. Но только при условии, что к ним относятся именно как к инструментам: требующим настройки, контроля и профессиональных рук.
Семь сценариев, описанных в этой статье, — не исчерпывающий список. Но они покрывают основные точки, где ИИ уже сейчас приносит измеримую пользу ИБ-подразделениям. Начать с одного из них, проверить результат и двигаться дальше — прагматичная стратегия, которая работает лучше, чем попытка автоматизировать всё и сразу.
В AZONE AI мы помогаем ИБ‑подразделениям находить и внедрять решения на основе ИИ, которые работают в реальной инфраструктуре — включая закрытые контуры и on‑premise среды. Если вы рассматриваете применение ИИ в процессах безопасности и хотите начать с пилотного проекта — мы готовы обсудить задачу.
Частые вопросы
Может ли ИИ полностью заменить аналитиков SOC?
Нет. ИИ берёт на себя рутинные, повторяющиеся задачи: приоритизацию алертов, первичную классификацию инцидентов, суммаризацию логов. Но принятие решений о реагировании, интерпретация контекста, коммуникация с бизнесом и работа со сложными, нестандартными инцидентами остаются задачей человека. Роль аналитика не исчезает — она смещается от разбора шума к анализу и принятию решений.
Какие задачи ИБ можно автоматизировать с помощью нейросетей уже сейчас?
Наиболее зрелые сценарии: ML-приоритизация алертов в SIEM, поведенческий анализ (UEBA), автоматический triage инцидентов, снижение ложных срабатываний DLP, анализ фишинговых писем и LLM-ассистенты для аналитиков. Каждый из них требует адаптации к конкретной инфраструктуре, но технологическая база для внедрения уже существует.
Обязательно ли разворачивать ИИ-решения on-premise?
Зависит от требований к защите данных. Если ИИ обрабатывает логи безопасности, содержание перехваченных писем или поведенческие профили пользователей, передача этих данных в облако может быть неприемлема — особенно для организаций с регуляторными ограничениями. В таких случаях on-premise или развёртывание в закрытом контуре — обоснованный выбор. Для менее чувствительных задач допустимы и облачные решения.
Сколько времени занимает пилотный проект по внедрению ИИ в SOC?
Типовой пилот на одном сценарии (например, ML-приоритизация алертов) при наличии подготовленных данных и определённых критериев успеха занимает от нескольких недель до двух-трёх месяцев. Основное время уходит не на развёртывание модели, а на подготовку данных, интеграцию с источниками событий и калибровку.
Каковы главные риски при внедрении ИИ в процессы информационной безопасности?
Ключевые риски: низкое качество данных, на которых обучается модель; ложное чувство безопасности при чрезмерном доверии к автоматическим решениям; «галлюцинации» LLM при генерации playbook'ов и отчётов; утечка чувствительных данных через облачные ИИ-сервисы; деградация модели со временем без замкнутого цикла обратной связи. Все эти риски управляемы, но требуют осознанного подхода.
Технический документ: Архитектура внедрения LLM в закрытом контуре КИИ
PDF ~20 страниц для CISO и архитекторов. Регуляторный контекст, эталонная архитектура, чек-лист готовности к пилоту.
Начните с пилотного проекта
За 4–8 недель мы внедрим ИИ-решение для вашего SOC на вашей инфраструктуре.
Обсудить пилот