Как ИИ сокращает время поиска документов с часов до минут
Разбор кейса внедрения нейросетевого архива в крупном промышленном холдинге. Семантический поиск по архиву из 5 миллионов скан-копий.
Контекст и проблема
Крупный промышленный холдинг потратил два года на оцифровку бумажного архива — и получил 5 миллионов файлов, в которых невозможно ничего найти. Рассказываем, как семантический поиск на базе ИИ решил эту задачу и что нужно, чтобы повторить результат у себя.
Типичный архив крупного холдинга — это договоры, акты, счета-фактуры, протоколы, приказы, техническая документация и переписка за 15–20 лет. После сканирования всё это превращается в 5 миллионов PDF-файлов на сетевых хранилищах. Часть документов отсканирована ровно и чётко, часть — это кривые скан-копии с пятнами и рукописными пометками.
Формально оцифровка завершена. Фактически — сотрудники продолжают звонить в архив и ждать, пока оператор вручную найдёт нужный скан. Причина проста: у большинства файлов нет нормальных метаданных. Имена вроде scan_0048712.pdf не говорят ни о чём, а ручная разметка 5 миллионов документов нереальна.
Какие запросы приходят каждый день
Ни один из этих запросов не решается простым поиском по имени файла.
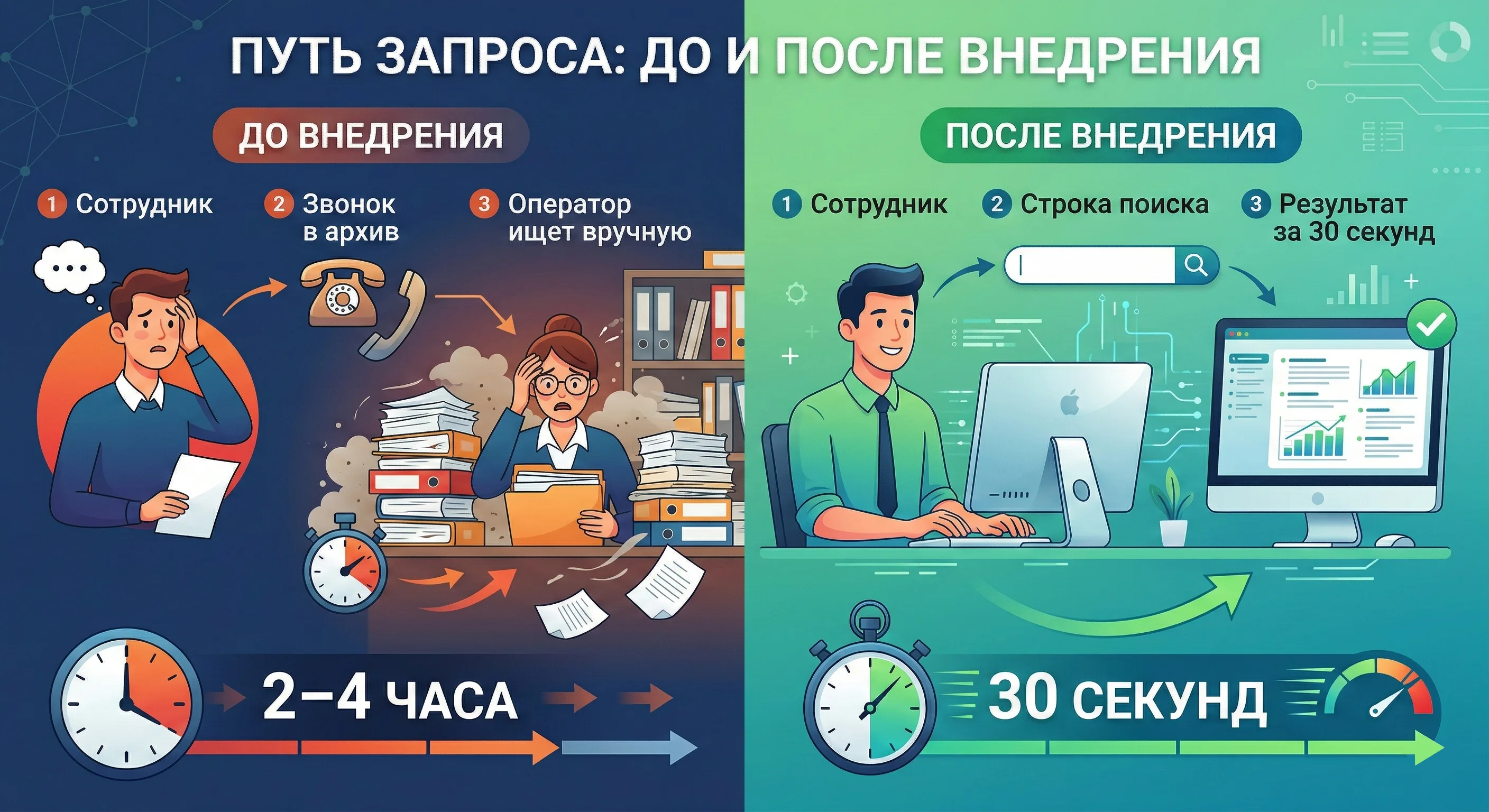
Типовой маршрут поискового запроса: было и стало
Почему поиск по ключевым словам — тупик
Первая мысль: «Давайте прогоним всё через OCR и будем искать по тексту». Звучит логично, но на практике разбивается о несколько стен.
OCR ошибается
Даже хорошие движки на сканах среднего качества дают 2–5% ошибок посимвольно. «Договор» превращается в «Дoговор» (с латинской «o»), номер «ДП-2018/0451» — в «ДП-2О18/О451». Полнотекстовый поиск по точному совпадению такие документы не найдёт.
Синонимы и вариации
Один и тот же документ в разных подразделениях называют «договор», «контракт», «соглашение». Акт выполненных работ — «акт сдачи-приёмки», «закрывающий акт», просто «закрывашка». Ключевое слово ловит только одну формулировку.
Шум от печатей и штампов
OCR пытается распознать текст внутри круглых печатей и угловых штампов. Результат — мусорные строки, которые засоряют индекс и снижают точность.
Рукописные пометки
Резолюции, визы, подписи — всё это добавляет «фантомный» текст в распознанный слой.
Решение: семантический ИИ-поиск
Идея семантического поиска в том, что система ищет не по буквальному совпадению слов, а по смыслу. Каждый фрагмент текста (страница или абзац) превращается в числовой вектор — набор из нескольких сотен чисел, который кодирует смысл написанного.
Когда сотрудник вводит запрос, система превращает его в такой же вектор и находит ближайшие по смыслу фрагменты в базе. «Договор на перевозку» найдёт и «контракт на транспортные услуги», и «соглашение о грузоперевозках» — потому что смысл один.
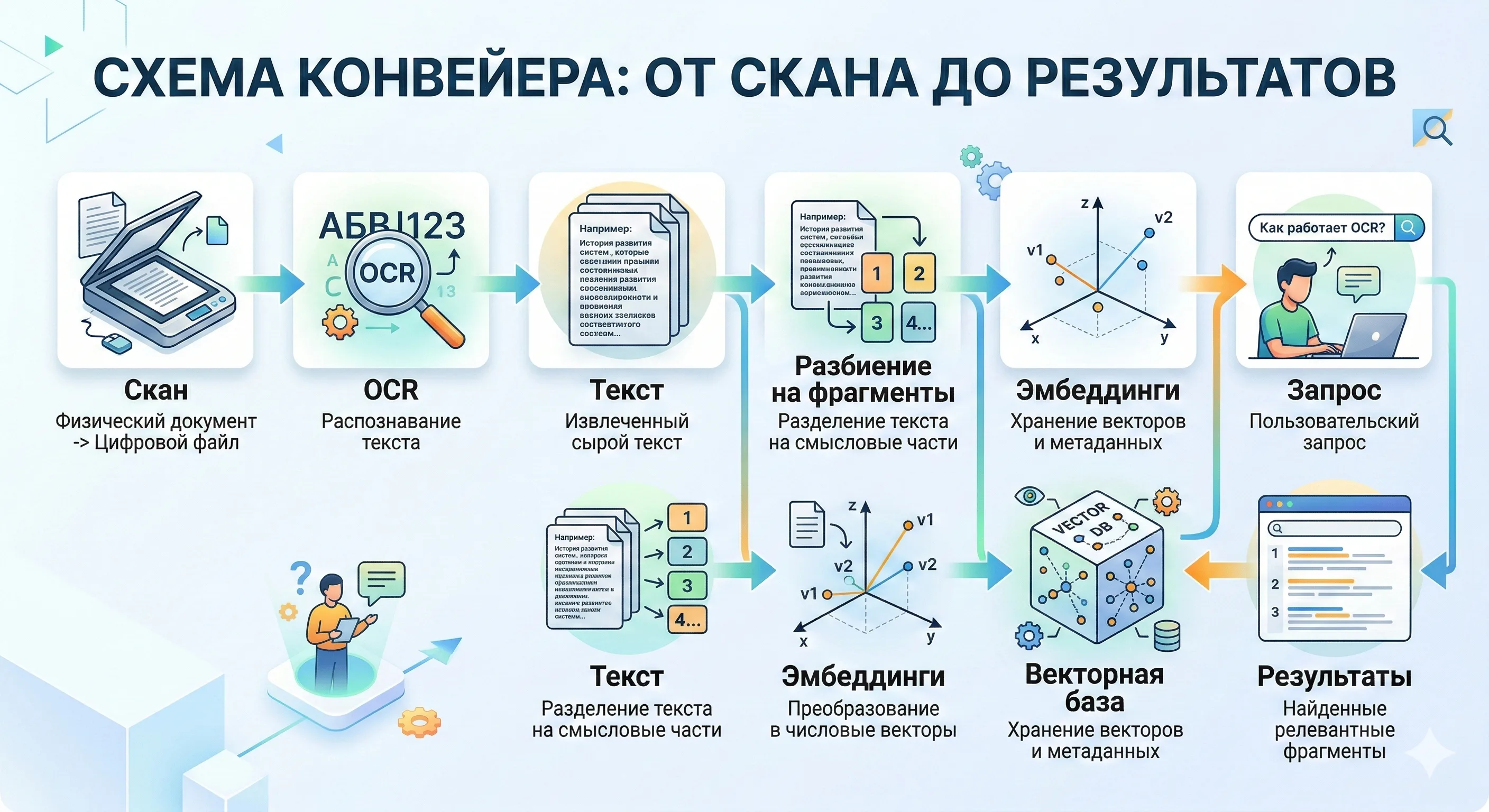
Конвейер обработки: от скана до поиска по смыслу
Как это работает
OCR и контроль качества
На входе — скан. OCR-движок распознаёт текст, а параллельно система оценивает качество: уровень уверенности распознавания, наличие перекосов, процент «мусорных» символов. Если качество ниже порога — скан уходит на повторную обработку с предварительной коррекцией.
Разбиение на фрагменты (chunking)
Распознанный текст разрезается на фрагменты по 300–500 слов с перекрытием. Перекрытие нужно, чтобы не потерять контекст на стыке двух кусков: если нужная фраза попала на границу, она окажется в обоих соседних фрагментах.
Векторная база
Каждый фрагмент прогоняется через языковую модель и превращается в вектор. Все векторы складываются в специализированную векторную базу данных, оптимизированную для быстрого поиска ближайших соседей среди миллионов записей.
Гибридный поиск
Лучше всего работает гибрид: семантический поиск (по смыслу) + классический полнотекстовый (по ключевым словам). Семантика ловит синонимы и перефразировки, а ключевые слова — точные номера договоров, ИНН, даты. Результаты двух каналов объединяются и взвешиваются.
Переранжирование (re-ranking)
Первичный поиск возвращает 50–100 кандидатов. Затем более тяжёлая модель переранжирования оценивает каждого кандидата в паре с запросом и выстраивает финальный рейтинг. «Второй тур» — медленнее, но точнее, и работает только с короткими списками.
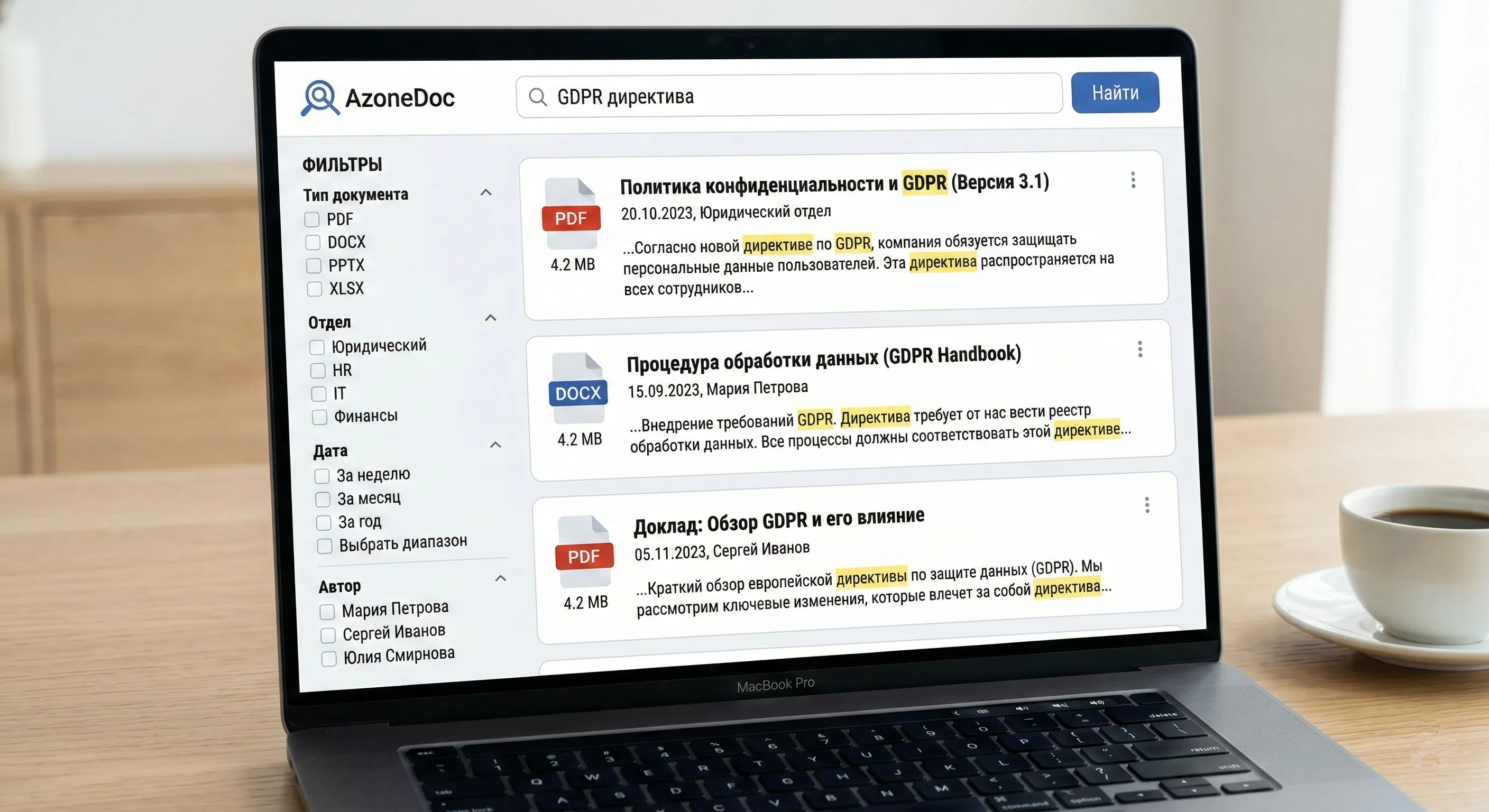
Интерфейс поиска: запрос на естественном языке, подсветка релевантных фрагментов, фильтры
Результаты
Пилот на 800 000 сканов занял 3 месяца. После масштабирования на полный архив (5 млн документов) зафиксированы следующие показатели:
| Метрика | Было | Стало | Изменение |
|---|---|---|---|
| Среднее время поиска документа | 2–4 часа | 1–3 минуты | ×60–80 быстрее |
| Доля запросов без обращения в архив | ~15% | ~82% | +67 п.п. |
| Релевантность Top-3 | — | 78% | — |
| Релевантность Top-5 | — | 91% | — |
| Скорость индексации | — | ~120 000 сканов/сут. | — |
| Экономия времени архивного отдела (12 чел.) | — | ~950 чел.-ч/мес. | — |
| Подготовка пакета для аудита | 3–5 рабочих дней | 2–4 часа | ×10–15 быстрее |
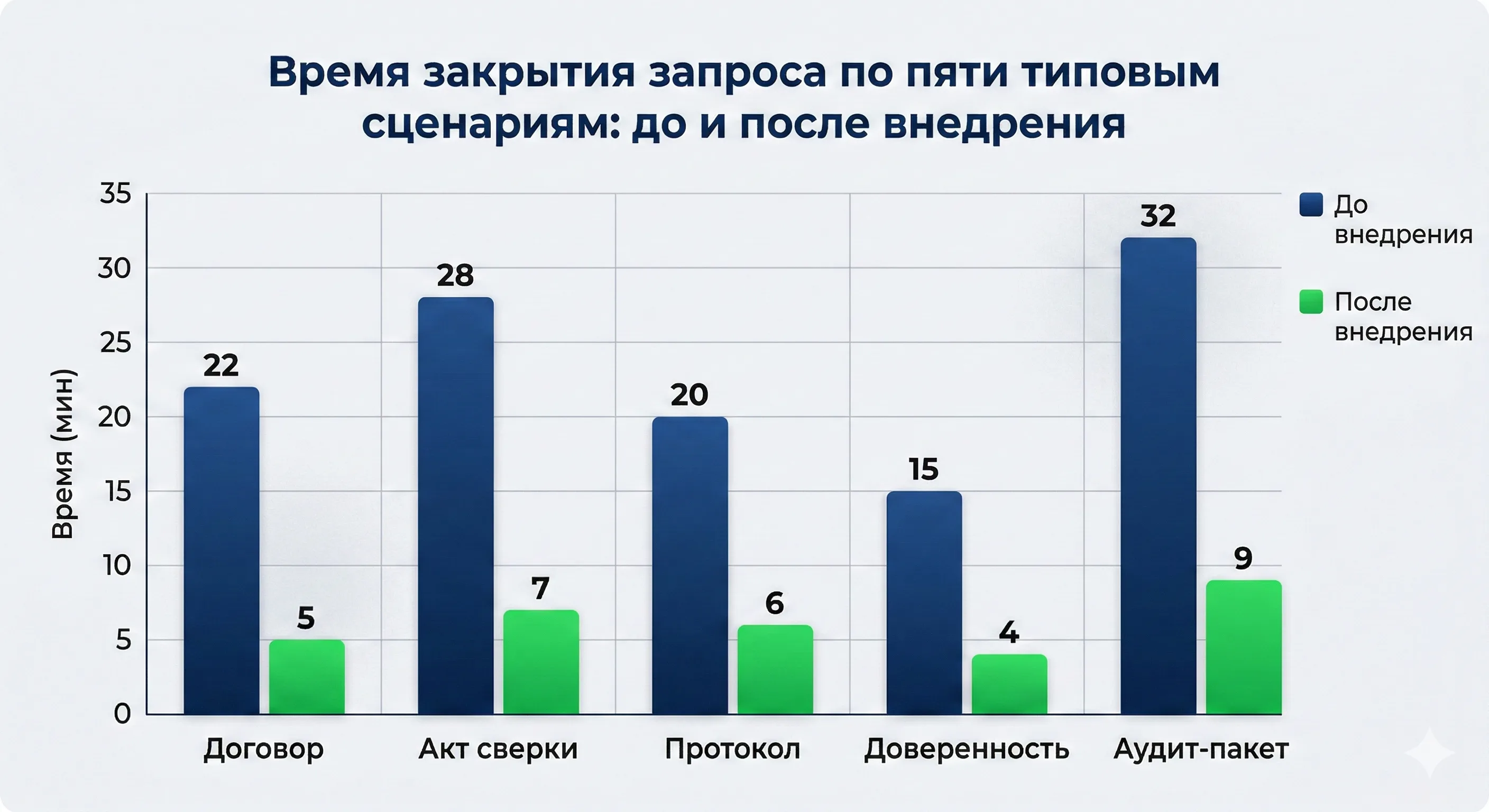
Время закрытия запроса по пяти типовым сценариям: до и после внедрения
Риски и как их закрывали
Безопасность и доступы
Не все документы доступны всем. Система интегрирована с корпоративным каталогом (Active Directory) и реализует ролевую модель доступа (RBAC). Сотрудник юридического отдела видит одну выдачу, сотрудник производственного — другую. Все поисковые запросы журналируются.
Утечки и конфиденциальность
Векторная база и модели развёрнуты на собственных серверах холдинга внутри защищённого контура. Никакие данные не передаются за периметр. Для обработки используются модели, которые запускаются локально.
Качество OCR и «мусорные» сканы
Часть архива оцифрована плохо: косые скан-копии, выцветшие чернила, двусторонние документы с просвечиванием. Для них применяется предобработка изображений (выравнивание, повышение контраста) перед OCR. Документы с неприемлемым качеством выносятся в отдельную очередь для ручной проверки.
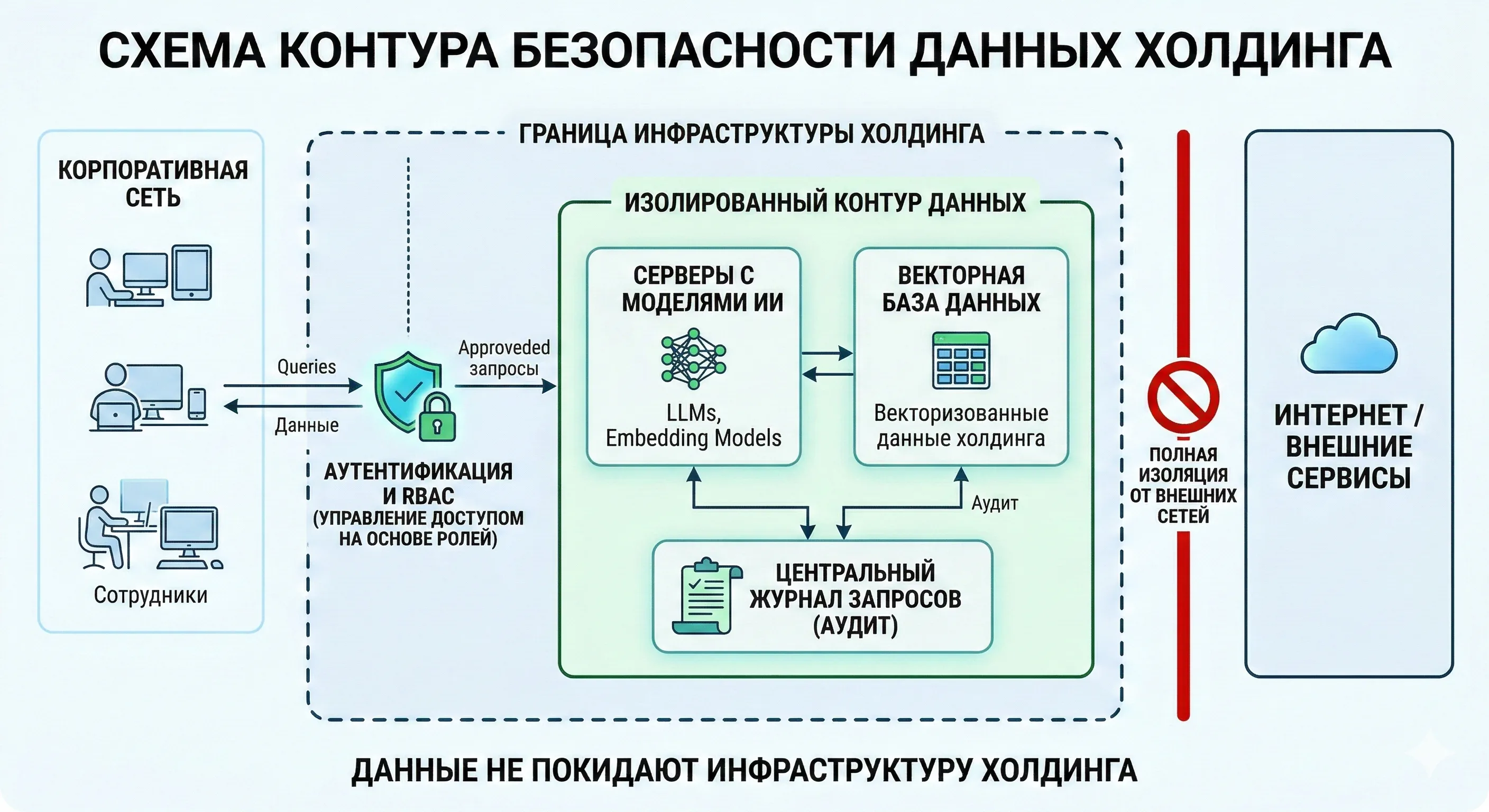
Схема контура безопасности: данные не покидают инфраструктуру холдинга
Таймлайн проекта
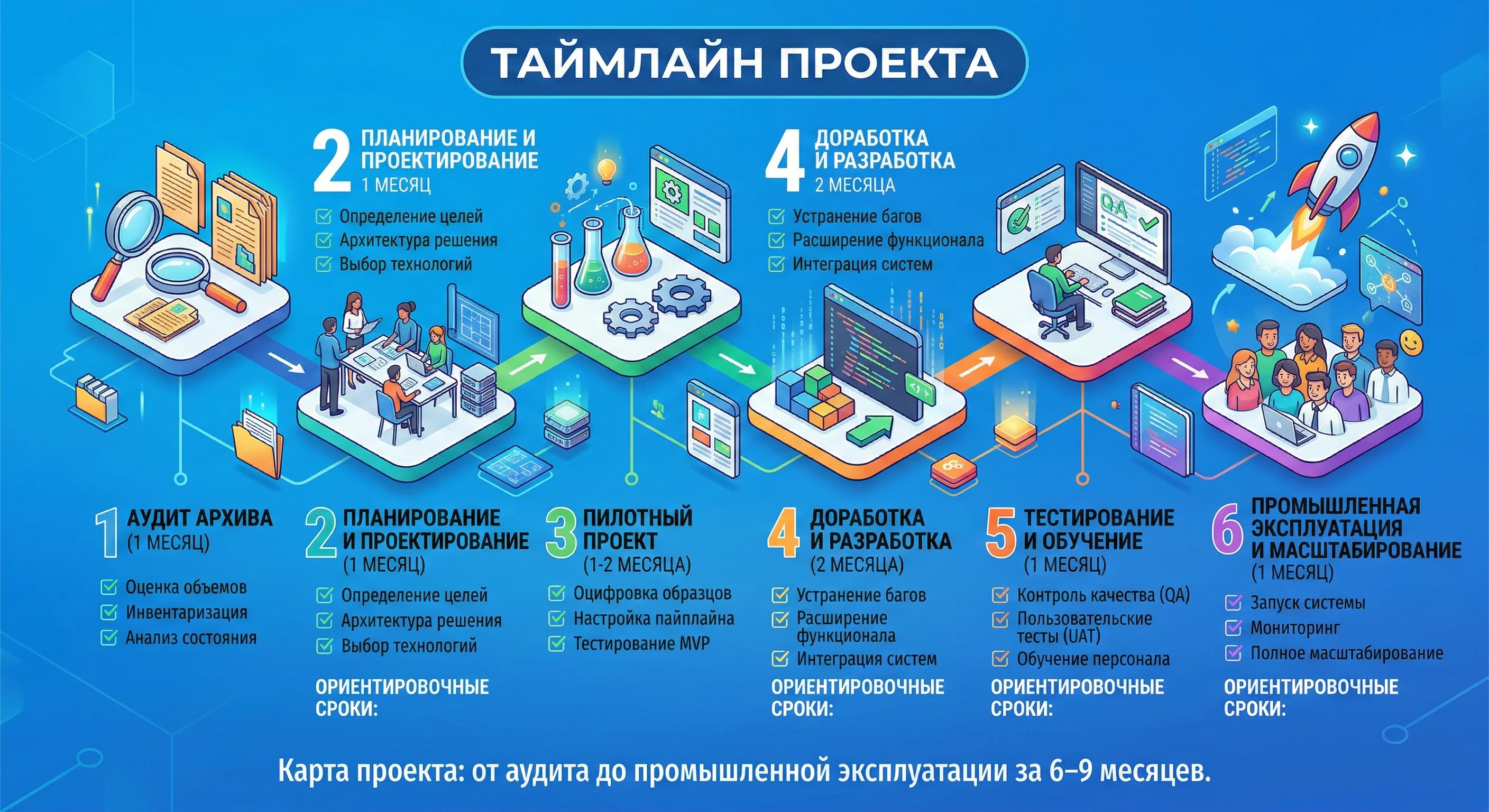
От аудита до промышленной эксплуатации за 6–9 месяцев
- · Оценка объёмов
- · Инвентаризация
- · Анализ состояния
- · Определение целей
- · Архитектура решения
- · Выбор технологий
- · Оцифровка образцов
- · Настройка пайплайна
- · Тестирование MVP
- · Устранение багов
- · Расширение функционала
- · Интеграция систем
- · Контроль качества
- · Пользовательские тесты
- · Обучение персонала
- · Запуск системы
- · Мониторинг
- · Полное масштабирование
Вывод
Семантический поиск — это не экзотика. Это инженерная задача с известными решениями, проверенными стеками и реальными ROI-метриками. Если у вашей организации есть большой документальный архив и сотрудники тратят часы на поиск информации — это решаемо.
AzoneDoc разворачивается на вашей инфраструктуре: данные не покидают периметр, система интегрируется с 1С, SAP, Directum и ELMA. Обсудим ваш архив?
Начните с пилотного проекта
За 4–8 недель мы развернём решение на вашей инфраструктуре.
Обсудить пилот