Открытые данные и ИИ: что за последние пару лет действительно изменилось в конкурентной разведке
Вакансии, тендеры, пресс-релизы, технологический стек — что машина уже читает хорошо, а что пока читать за ней
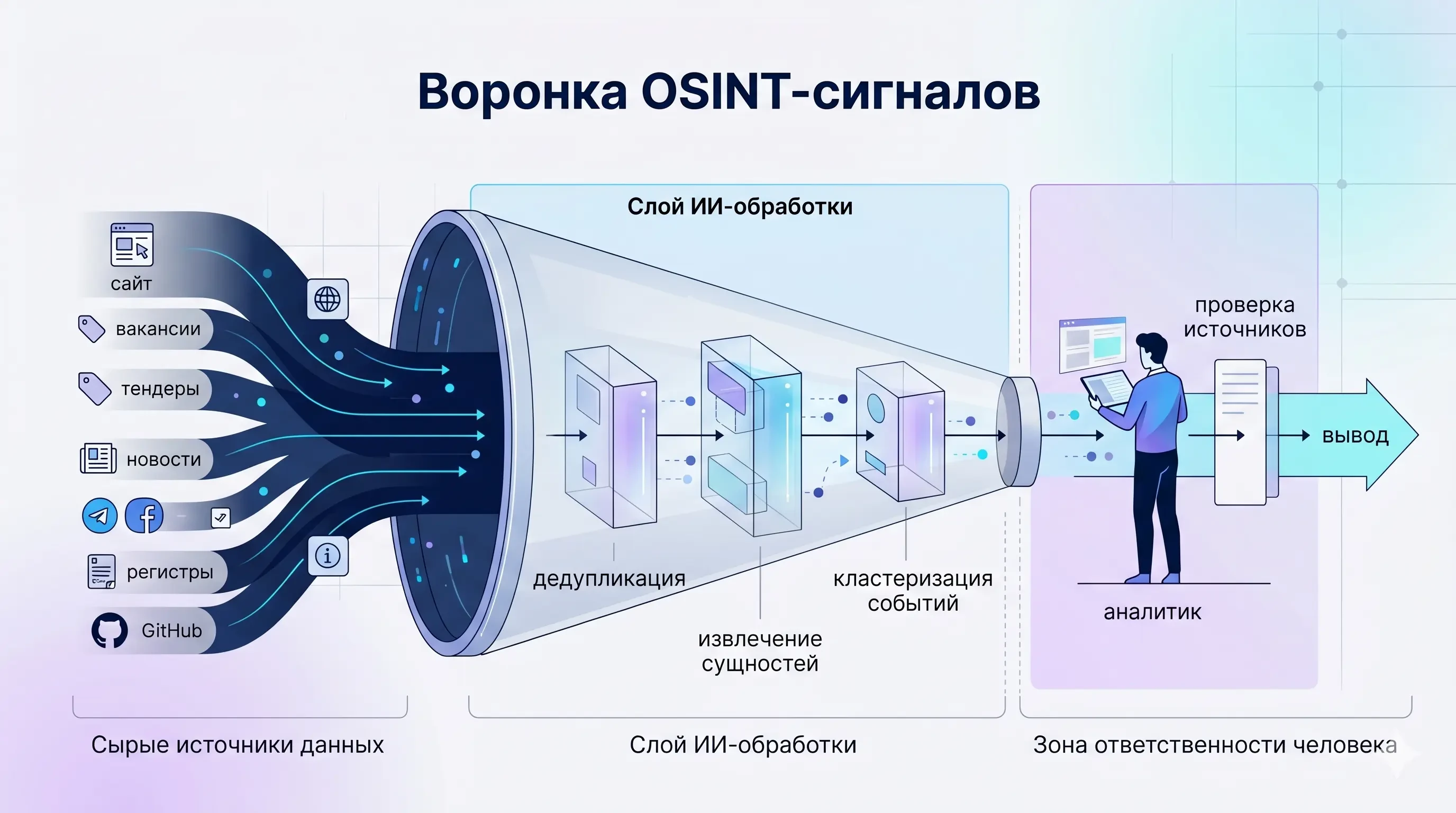
Открытых сигналов о конкурентах стало слишком много, чтобы обрабатывать их руками. ИИ здесь действительно выручает. Но та же модель, которая за минуту перескажет пятьдесят пресс-релизов, с такой же уверенностью придумает сделку, которой не было. Ниже — о том, где ИИ в OSINT реально помогает, где он опасен и как собрать процесс, в котором ошибки успевают всплыть до того, как попадут в отчёт руководству.
Почему OSINT перестал помещаться в голову аналитика
Ещё десять лет назад конкурентная разведка в средней компании выглядела так: один человек, подписка на пару отраслевых дайджестов, папка с вырезками и квартальный отчёт. Сегодня этот подход уже не работает — и не потому, что кто-то перестал его ценить. О любой зрелой компании в открытом доступе лежат десятки тысяч сигналов: сайт и блог, вакансии, истории тендеров и закупок, пресс-релизы, выступления на конференциях, соцсети сотрудников, GitHub, патенты, судебные дела, сведения из госреестров, кэш старых версий страниц в Web Archive. Проблема давно не в доступе. Проблема в том, что читать всё это некому, а связи между фрагментами никто не удерживает в голове.
Отсюда и интерес к ИИ. Языковые модели умеют быстро читать и обобщать, вытаскивать из текста факты, кластеризовать повторы, собирать сравнительные таблицы. На рутине это выручает сильно. Интерпретация и стратегические выводы пока остаются за человеком, и с заметным отрывом.
У этой автоматизации есть оборотная сторона, которую обычно вспоминают во вторую очередь. ИИ выдаёт ответ с одинаково уверенной интонацией, когда он прав, и когда галлюцинирует. Поэтому честный разговор о качестве конкурентной разведки с ИИ — это не про «какую модель выбрать», а про дисциплину процесса. На этом и сосредоточимся.
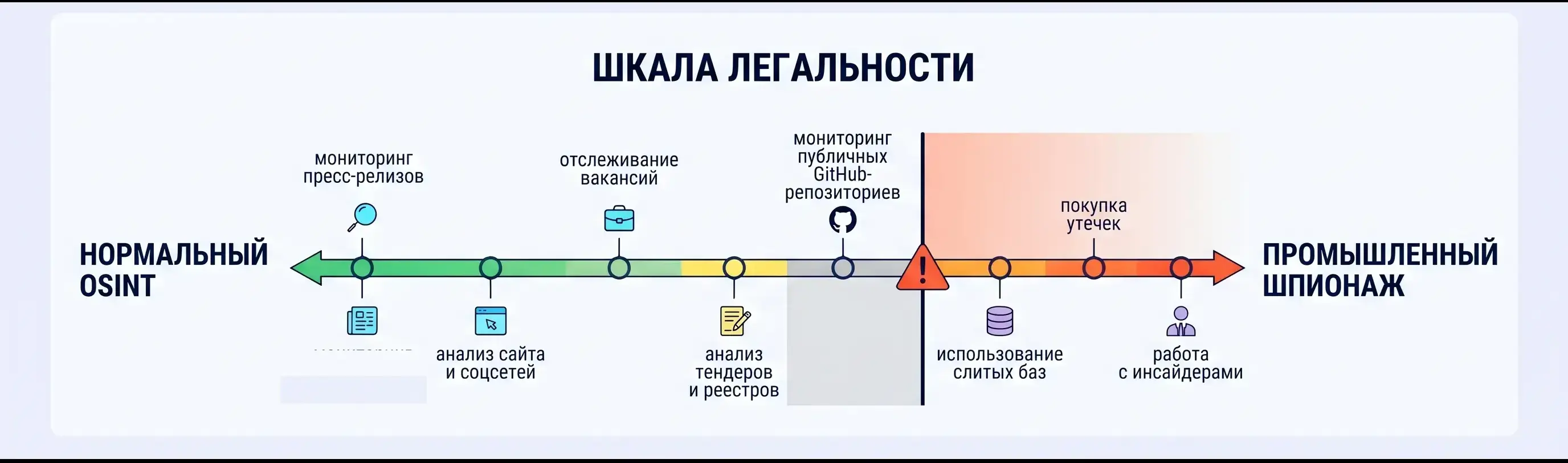
Термины и где проходит граница
В корпоративных разговорах «конкурентная разведка», «OSINT» и «мониторинг» часто перемешиваются, а граница между нормальной работой и сомнительными практиками теряется. Несколько определений, чтобы дальше не путаться.
Процесс, а не отчёт. Компания регулярно собирает и интерпретирует информацию о рынке, конкурентах, клиентах и технологиях, чтобы принимать решения раньше, чем ситуация ударит по выручке. Разовое исследование разведкой не является, сколь бы хорошо оно ни было сделано.
Open Source Intelligence — работа только с данными, полученными из открытых источников законным способом. Корпоративные сайты, СМИ, соцсети, госреестры, открытые API, патентные базы, картотеки судебных дел. Взломы, социальная инженерия и инсайдеры в чужих компаниях сюда не относятся.
Всё, что компания и её сотрудники оставляют наружу намеренно или ненамеренно. От вакансий и публичных выступлений до резюме бывших сотрудников и коммитов в открытых репозиториях. Та самая область, где автоматизация даёт самый очевидный выигрыш.
Собирать и обрабатывать то, что компания выложила сама, — в порядке вещей. Массово выгружать персональные данные, обходить платные доступы, нарушать пользовательские соглашения, подкупать информаторов — уже нет. ИИ в этой разметке ничего не меняет.
152-ФЗ и агрегация. Даже публично размещённое резюме остаётся персональными данными. Массовая их агрегация — например, сбор всех резюме сотрудников конкурента по Москве — легко создаёт состав нарушения. Это надо учитывать на старте, а не после первого письма от юриста.
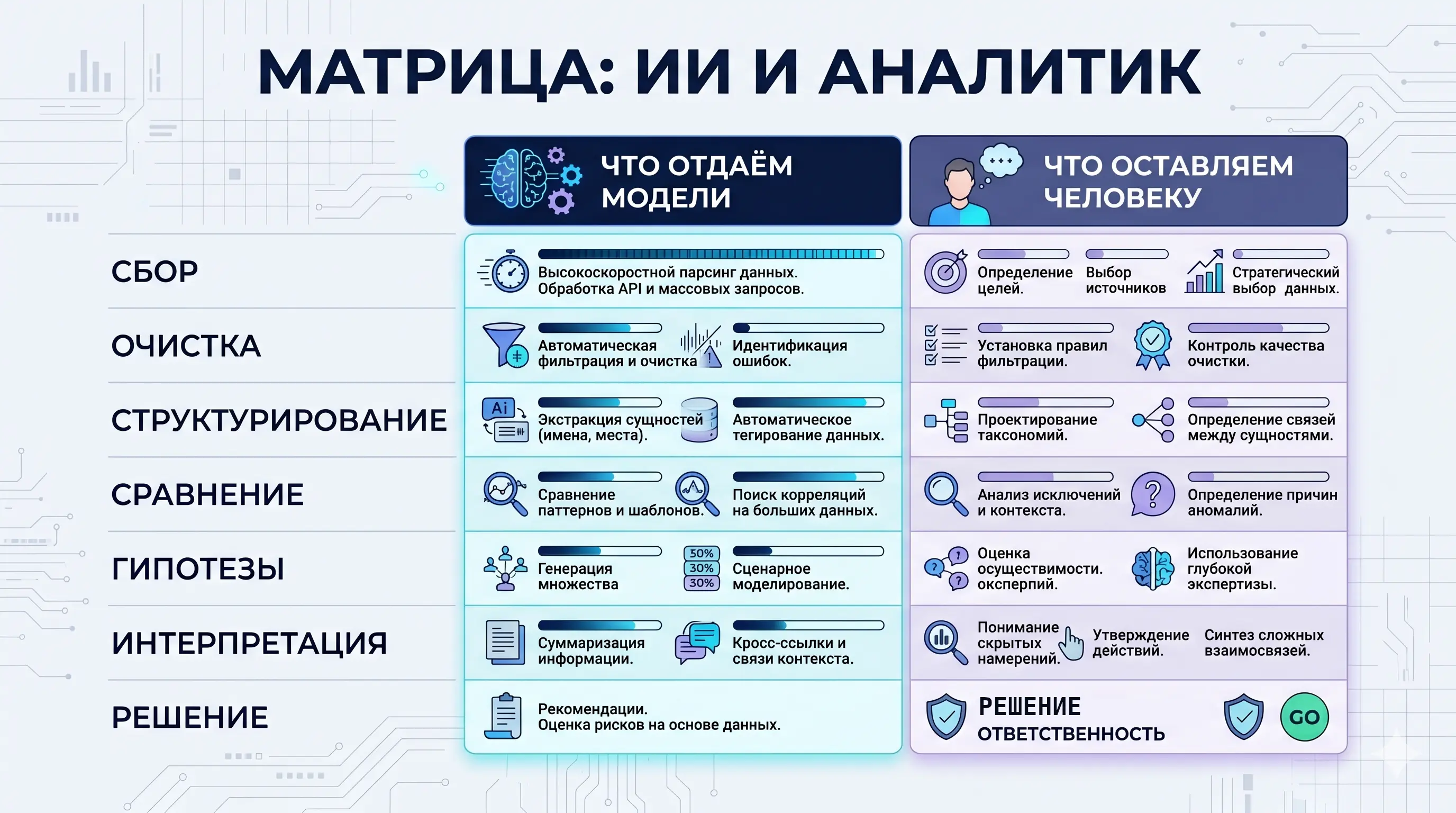
Что ИИ действительно меняет в OSINT
Выигрыш складывается из разных по природе эффектов. Если их не разделять, легко либо переоценить пользу, либо, наоборот, пройти мимо чего-то важного.
Самый понятный слой. Модель за двадцать минут читает годовую подшивку блога конкурента, возвращает хронологию ключевых тем, и аналитик дальше идёт читать в оригинал только то, что того стоит. Экономия времени — в разы, и это воспроизводимо.
Одно и то же событие обычно звучит в десятках источников: перепечатки, цитаты, пересказы. ИИ кластеризует сообщения по событиям — и когда из ленты уходят повторы, становится видно то, что раньше в ней тонуло.
Модели превращают сплошной текст в структуру: компании, люди, продукты, технологии, даты, суммы, роли. После этого становятся возможны запросы другого класса: кто нанял больше всего ML-инженеров, у кого общие подрядчики, какая технология впервые засветилась в вакансиях.
Продукты, позиционирование, команды, география, ценовая политика там, где она открыта. Результат надо перечитывать глазами — таблицы почти всегда содержат одну-две неточности. Но как стартовый черновик сравнительный срез делается за минуты, а не за дни.
Если регулярно снимать снимки сайтов, документации, магазина приложений, вакансий, — ИИ покажет, что за неделю поменялось. Поодиночке такие микросигналы ничего не значат. Вместе они иногда складываются в стратегию, о которой конкурент ещё не объявил.
Формально не анализ, но неожиданно полезно. Модель получает набор сигналов за квартал и предлагает: компания готовится к выходу в новый сегмент, перестраивает команду, сворачивает направление. Это догадка, а не вывод. Но одна удачная гипотеза экономит дни ручной работы.
Практические сценарии
Теория без задач остаётся теорией. Ниже — набор сценариев, где ИИ уже сейчас даёт измеримый эффект.
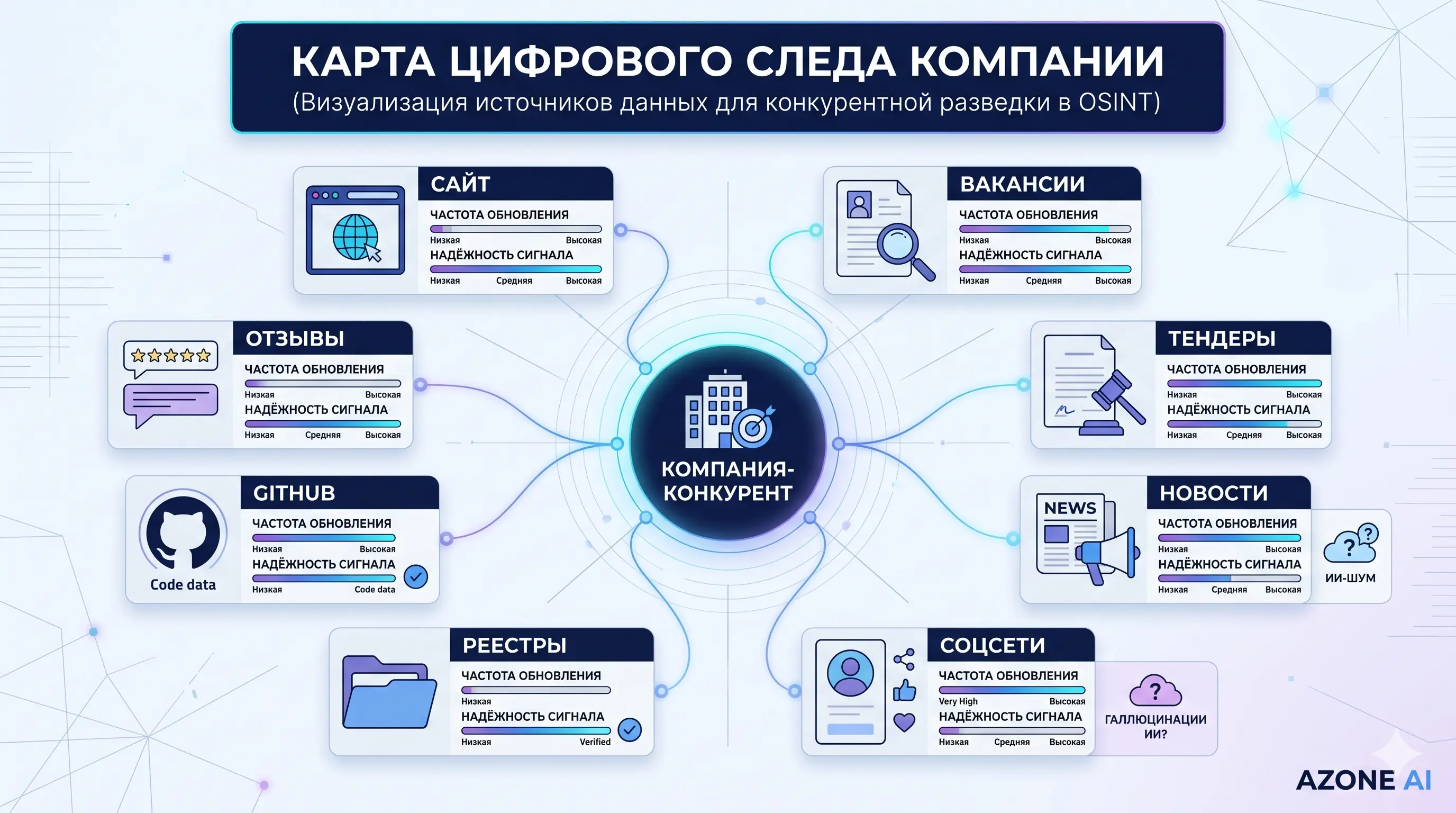
Типовой запрос: «разберись, что компания X говорит о себе публично». ИИ-ассистент проходит по корпоративному сайту, блогу, разделу для инвесторов, партнёрским страницам, кейсам — и выдаёт позиционирование, целевые сегменты, заявленные продукты, отраслевые референсы, технологические упоминания, географию. Отдельно полезно просить модель зафиксировать разницу между маркетинговой декларацией и тем, что реально подтверждается кейсами. Нестыковки здесь — сами по себе ценный сигнал.
Вакансии — самый недооценённый источник. Из них восстанавливается технологический стек, приоритеты роста, география экспансии, иногда продуктовые планы. Тендеры и закупки в российском контексте — богатая и юридически чистая поляна: история участия восстанавливает клиентскую базу, типовые суммы контрактов, отраслевую специализацию. Соцсети и конференции дают срез публичной повестки; подкасты и YouTube-выступления модели сегодня неплохо расшифровывают и реферируют.
Регулярное сопоставление снимков продуктовых страниц, документации, публичных API, описаний в магазинах приложений — плюс пресс-релизы о релизах — даёт картину изменений продукта. Модель не просто показывает дифф, а интерпретирует: появилась функция X, исчезло упоминание сегмента Y, изменилась тарифная логика. Часть этих сигналов значимее, чем годовой отчёт о стратегии.
Пресс-релизы о партнёрствах, совместные кейсы, упоминания на сайтах интеграторов и вендоров восстанавливают экосистему вокруг конкурента. ИИ агрегирует такие сигналы в карту связей: кто с кем работает, где общие клиенты, где компания опирается на подрядчиков, а где развивает собственную экспертизу. Такая карта часто объясняет больше, чем публичная стратегия.
Когда сигналов накапливается достаточно, ИИ выдаёт черновик SWOT-подобного разбора. Повторяющиеся темы удачных кейсов, устойчивый найм, публичные признания — правдоподобные плюсы. Жалобы клиентов в открытых источниках, судебные разбирательства, уход ключевых людей, хронически не закрывающиеся вакансии — минусы. Ещё раз: черновик. Перечитывать обязательно.
Где ИИ ломается
У языковых моделей есть родовая особенность, которую не исправить правильным промптом: они возвращают вероятностный текст, а не проверенную истину. В OSINT-задачах это проявляется в нескольких типичных неприятностях.
Модель уверенно называет сумму сделки, дату назначения, технологию, которую компания якобы использует, — и всё это может оказаться склейкой из похожих контекстов. Особенно неприятны галлюцинации со ссылками на несуществующие источники: выглядит убедительно, а URL ведёт в никуда.
Если два источника говорят разное — там и начинается настоящая аналитическая работа. Какой источник надёжнее? Что стоит за расхождением? Модель по умолчанию стремится выдать согласованный ответ и противоречия прячет. Отчёт выглядит стройно — ровно до того момента, как кто-то сверит его с первоисточниками.
Если в запрос зашита гипотеза, модель с высокой вероятностью найдёт ей «подтверждение» в тексте. Это делает ИИ плохим инструментом для проверки собственных идей и хорошим — для первичного сбора материала.
Модели без подключения к актуальным данным дают аккуратную, но вчерашнюю картину. Для OSINT, где важна именно свежесть, контур без интеграции с живыми источниками почти бесполезен.
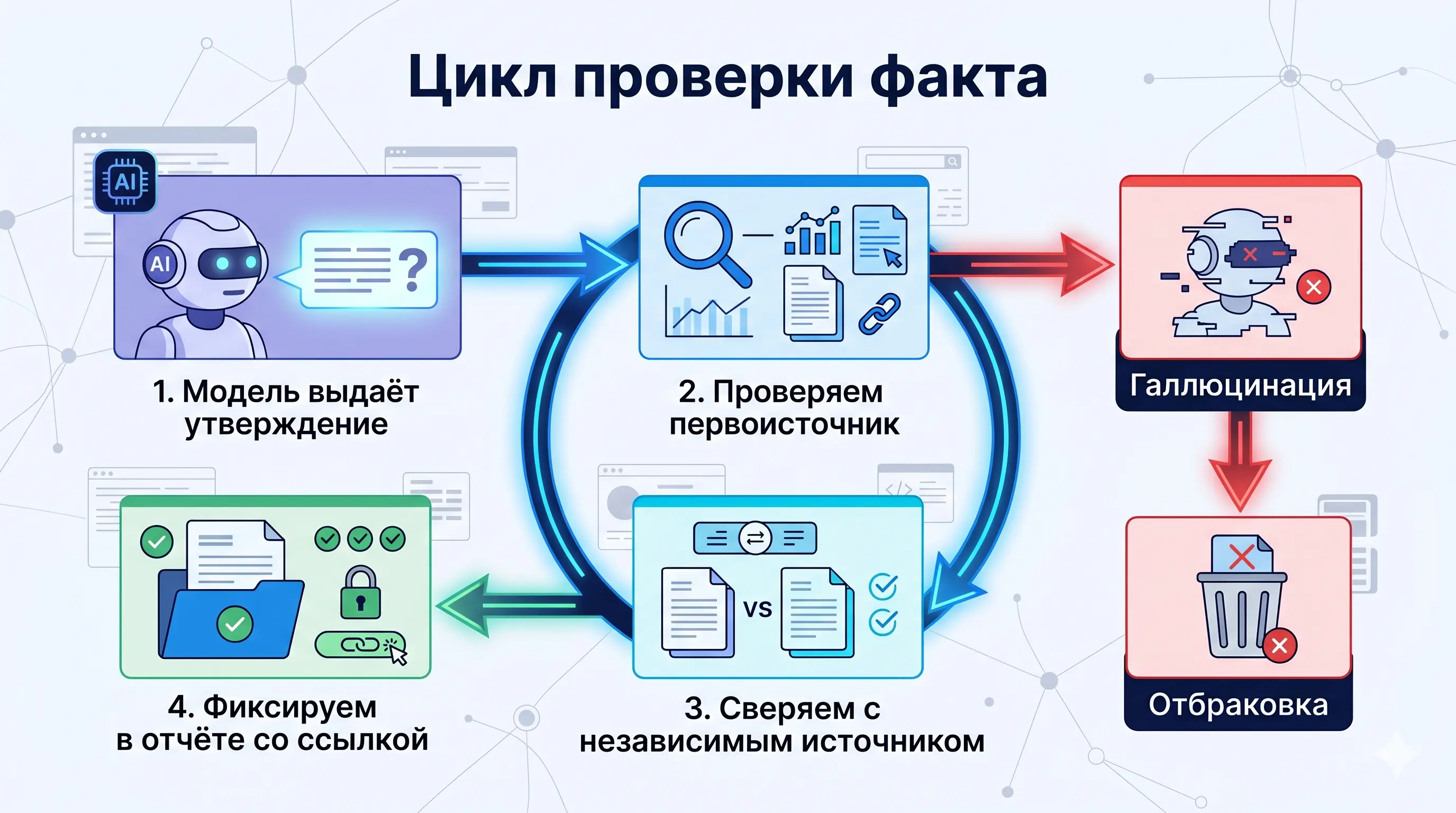
Рабочий принцип. Вывод не «не пользоваться», а «не пользоваться без контура проверки». Первоисточник должен оставаться проверяемым: каждое утверждение в итоговом отчёте — со ссылкой, каждая ключевая цифра — подтверждена человеком в оригинале. Без этого любая разведка с ИИ рано или поздно превращается в генератор правдоподобного вымысла.
Риски и ограничения
Помимо ошибок самой модели у автоматизированной конкурентной разведки есть ещё несколько родовых рисков, про которые в маркетинговых материалах обычно молчат.
Открытый доступ ещё не означает свободу действий. Пользовательские соглашения сайтов, требования закона о персональных данных, авторские права на публикации остаются в силе. В российской практике это в первую очередь 152-ФЗ и сопутствующие нормы: даже публично размещённое резюме — персональные данные, и массовая их агрегация несёт юридические риски. Парсинг в нарушение правил сервиса — отдельный сюжет, к которому стоит подходить так же внимательно, как к вопросу об авторском праве.
Конкурентная разведка и промышленный шпионаж — разные вещи. Разница должна удерживаться не только юридически, но и культурно. Простое правило: если методику нельзя спокойно объяснить собственному юристу, клиенту и регулятору — её не надо применять. Публичные данные о сотрудниках конкурента тоже не повод для навязчивых коммуникаций или социальной инженерии.
Автоматизация соблазняет собирать «всё». Резюме, личные посты, контакты, утечки — всё это легко оказывается в периметре, если заранее его не ограничить. Работающий способ — заранее описать конкретные источники и сущности, которые интересны, и не расширять периметр без явного повода. Иначе компания получает не разведку, а юридическую проблему с отложенным взрывом.
OSINT видит только то, что конкурент показывает наружу. Существенная часть стратегии в открытые источники не попадает никогда. Самый опасный когнитивный эффект — когда объём собранных данных создаёт ощущение, что картина собрана. На практике слепая зона есть всегда. Любой вывод лучше формулировать с пометкой об этой зоне, а не скрывать её за стройностью отчёта.
Чем аккуратнее выглядит ответ модели, тем сильнее искушение принять его без проверки. Отчёты с графиками и стройной аргументацией вызывают больше доверия, чем заслуживают. Рабочая привычка — относиться к любому выходу модели как к материалу от стажёра: понятно, структурно, иногда талантливо, но перед передачей наверх обязательно перечитать.
Как собрать рабочий контур OSINT с ИИ
Если спуститься с теории на землю и говорить о том, с чего разумно начинать, получается простая последовательность.
Попытка «автоматизировать всю конкурентную разведку» на старте проваливается примерно всегда. Рабочая конфигурация пилота — один-два ключевых конкурента и два-три приоритетных источника. Например: вакансии, пресс-релизы и тендеры. На таком периметре за две-три недели собирается полный цикл — сбор, обработка, проверка, отчёт, — и становится видно, что модель делает хорошо, а где нужна ручная доводка.
Автоматизируется то, что регулярно повторяется и не требует интерпретации: сбор новых материалов, дедупликация, извлечение сущностей, сводки за период. Сравнения и дифф-отчёты — следующий слой, уже с аккуратной ручной проверкой. Стратегические выводы автоматизировать не надо. Попытки обычно заканчиваются красивой презентацией, которая при первом разборе начинает сыпаться.
Если запросы к модели содержат чувствительную для компании информацию — внутренние гипотезы о конкурентах, клиентские пересечения, инсайдерские наблюдения — отправлять это в публичное облако рискованно. Запросы сами по себе становятся утечкой: по ним видно, кого компания изучает и что ищет. Для таких сценариев используются LLM в закрытом контуре — on-premise или в частном облаке под контролем самой компании.
Единой метрики, по которой можно сказать «контур работает», не существует. Но есть пять осей, которые вместе дают честную картину.
Какая доля приоритетных источников реально мониторится. Если из заявленных шести работает два — это не контур, а декорация.
Сколько проходит от появления события в открытых источниках до момента, когда оно появляется в ленте аналитика.
Доля алертов, которые оказываются одновременно истинными и релевантными. Шумный алерт хуже пропущенного.
Доля утверждений в итоговых отчётах, подтверждённых ссылкой на оригинал. Главная метрика зрелости контура.
Сколько выдвинутых гипотез удалось подтвердить или опровергнуть в разумные сроки. Ни одна из этих осей по отдельности не говорит всей правды. Вместе они показывают, что именно происходит: контур помогает принимать решения — или генерирует аккуратный шум.
Вывод
ИИ действительно ускоряет и углубляет конкурентную разведку. OSINT, который ещё недавно упирался во внимание одного человека, становится управляемым процессом. Компании, которые собрали такой контур раньше конкурентов, получают преимущество просто за счёт того, что видят рынок чётче.
Но выигрыш в итоге достаётся не тем, кто подключил модель, а тем, кто выстроил вокруг неё методику. Что собираем. Где границы. Как проверяем. Кто отвечает за решение. Модель — сильный инструмент, но она не умеет за компанию решать, что с этой разведкой делать дальше. И в ближайшее время научится вряд ли.
AZONE AI помогает выстраивать работу с LLM там, где запросы и данные не должны покидать периметр компании: от контура конкурентной разведки на открытых данных до развёртывания моделей on-premise с учётом требований ФСТЭК и ФСБ. Если вы оцениваете, как собрать такой процесс у себя — оставьте заявку на консультацию.
Актуальность материала
- Материал подготовлен по состоянию на апрель 2026 года.
- Упоминание требований 152-ФЗ и сопутствующих норм даётся в общем виде. Для конкретных сценариев обработки персональных данных рекомендуем отдельную юридическую оценку.
- Рекомендации по архитектуре контура OSINT носят общий характер. Подбор источников, метрик и модели развёртывания зависит от отрасли, модели угроз и зрелости процессов компании.
Похожие статьи
Соберите контур разведки под свой периметр
За 4–8 недель мы спроектируем архитектуру OSINT с автоматической обработкой и обязательным контуром верификации — с возможностью развёртывания LLM on-premise, если данные не должны покидать инфраструктуру.
Обсудить пилот